应用级服务发现
此文档已经不再维护。您当前查看的是快照版本。如果想要查看最新版本的文档,请参阅最新版本。
应用级服务发现简介
社区版本 Dubbo 从 2.7.5 版本开始,新引入了一种基于应用粒度的服务发现机制,这是我们为 Dubbo 适配云原生基础设施的一步重要探索,也是 Dubbo 迈出的重要一步。 简单来说,以前 Dubbo 是将接口的信息全部注册到注册中心,而一个应用实例一般会存在多个接口,这样一来注册的数据量就要大很多,而且有冗余。 全新的应用级服务发现机制是同一个应用实例仅在注册中心注册一条数据,注册中心的数据只与实例数量相关,大大降低了注册中心数据的存储与推送压力。
应用级服务发现的优势
从适配云原生以及可扩展性来看,Dubbo3 引入的应用级服务发现主要有以下优势
- 适配云原生微服务变革。云原生时代的基础设施能力不断向上释放,像 Kubernetes 等平台都集成了微服务概念抽象,Dubbo3 的应用级服务发现是适配各种微服务体系的通用模型。
- 提升性能与可伸缩性。支持超大规模集群的服务治理一直以来都是 Dubbo 的优势,通过引入应用级服务发现模型,从本质上解决了注册中心地址数据的存储与推送压力,相应的 Consumer 侧的地址计算压力也成数量级下降;集群规模也开始变得可预测、可评估(与 RPC 接口数量无关,只与实例部署规模相关)。
这样设计的全新的服务发现模型,在架构兼容性、可伸缩性上都给 Dubbo3 带来了更大的优势。
在架构兼容性上,Dubbo3 复用下层基础设施的服务抽象能力成为了可能;另一方面,如 Spring Cloud 等业界其它微服务解决方案也沿用这种模型, 在打通了地址发现之后,使得用户探索用 Dubbo 连接异构的微服务体系成为了一种可能。
接口粒度 VS 应用粒度
简单来说,以前 Dubbo2 是将接口的信息全部注册到注册中心,而一个应用实例一般会存在多个接口,这样一来注册的数据量就要大很多,而且有冗余。 应用级服务发现的机制是同一个应用实例仅在注册中心注册一条数据,对于注册中心、订阅方的存储压力都是一个极大的释放。 更重要的是,地址发现容量彻底与业务 RPC 定义解耦开来,整个集群的容量评估对运维来说将变得更加透明:部署多少台机器就会有多大负载, 不会像 Dubbo2 一样, 因为业务 RPC 重构就会影响到整个集群服务发现的稳定性。
假设应用 dubbo-application 部署了 3 个实例(instance1, instance2, instance3),并且对外提供了 3 个接口(sayHello, echo, getVersion)分别设置了不同的超时时间。
分别在 Dubbo2 和 Dubbo3 的服务发现机制下,注册到注册中心的数据是截然不同的。
接口粒度下注册中心中的数据
以 Dubbo2 当前的地址发现数据格式为例,它是"RPC 服务粒度"的,它是以 RPC 服务作为 key,以实例列表作为 value 来组织数据的:
"sayHello": [
{"application":"dubbo-application","name":"instance1", "ip":"127.0.0.1", "metadata":{"timeout":1000}},
{"application":"dubbo-application","name":"instance2", "ip":"127.0.0.2", "metadata":{"timeout":2000}},
{"application":"dubbo-application","name":"instance3", "ip":"127.0.0.3", "metadata":{"timeout":3000}},
],
"echo": [
{"application":"dubbo-application","name":"instance1", "ip":"127.0.0.1", "metadata":{"timeout":1000}},
{"application":"dubbo-application","name":"instance2", "ip":"127.0.0.2", "metadata":{"timeout":2000}},
{"application":"dubbo-application","name":"instance3", "ip":"127.0.0.3", "metadata":{"timeout":3000}},
],
"getVersion": [
{"application":"dubbo-application","name":"instance1", "ip":"127.0.0.1", "metadata":{"timeout":1000}},
{"application":"dubbo-application","name":"instance2", "ip":"127.0.0.2", "metadata":{"timeout":2000}},
{"application":"dubbo-application","name":"instance3", "ip":"127.0.0.3", "metadata":{"timeout":3000}}
]
应用粒度下注册中心中的数据
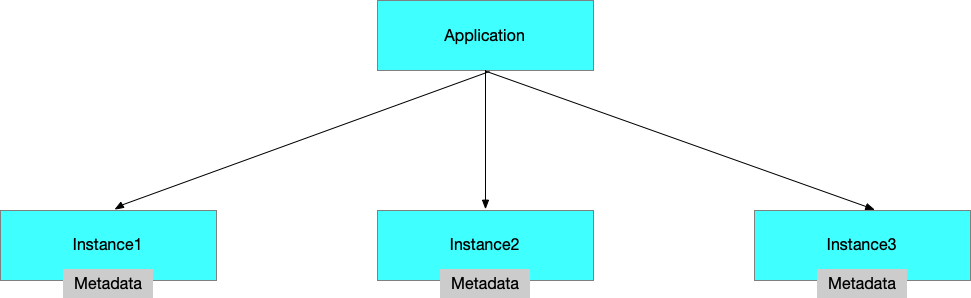
而我们新引入的"应用级服务发现",它以应用名作为 key,以这个应用部署的一组实例列表作为 value。这带来两点不同:
- 数据映射关系变了,从
RPC Service->Instance变为Application->Instance; - 数据变少了,注册中心没有了 RPC Service 及其相关配置信息。
"dubbo-application": [
{"name":"instance1", "ip":"127.0.0.1", "metadata":{"timeout":1000}},
{"name":"instance2", "ip":"127.0.0.2", "metadata":{"timeout":2000}},
{"name":"instance3", "ip":"127.0.0.3", "metadata":{"timeout":3000}}
]
通过上面的数据对比我们可以清楚的看到"应用粒度"相对"接口粒度"的数据量少了很多,尤其是在大规模集群架构的场景下提升是非常明显的。
应用级服务发现的意义
探索云原生之路
云原生带来了底层基础设施,应用开发、部署和运维等全方位的变化。在基础设施层面,因为基础设施调度机制变化,应用的生命周期、服务治理等方面都涉及到了非常多的变化。 Service Mesh 作为云原生微服务解决方案,Mesh 为跨语言、sdk 升级等提供了解决方案,Dubbo 要与 Mesh 协作,做到功能、协议、服务治理等多方便的适配。 Mesh 尚未大规模铺开,且其更适合对流量管控更关注的应用,传统 SDK 的性能优势仍旧存在,两者混部迁移场景可能会长期存在,针对这些问题和背景 Dubbo 将会做出如下改善。
- 生命周期:Dubbo 与 Kubernetes 调度机制绑定,保持服务生命周期与 Pod 容器等生命周期的自动对齐
- 治理规则:服务治理规则在规则体、规则格式方面进行优化,如规则体以 YAML 描述、取消过滤规则对 IP 的直接依赖,定义规则特有的 CRD 资源等
- 服务发现:支持 K8S Native Service 的服务发现,包括 DNS、API-Server,支持 xDS 的服务发现
- Mesh 架构协作:构建下一代的基于 HTTP/2 的通信协议,支持 xDS 的标准化的数据下发
- 新一代的 RPC 协议和应用级服务发现模型将会是这一部分的前置基础
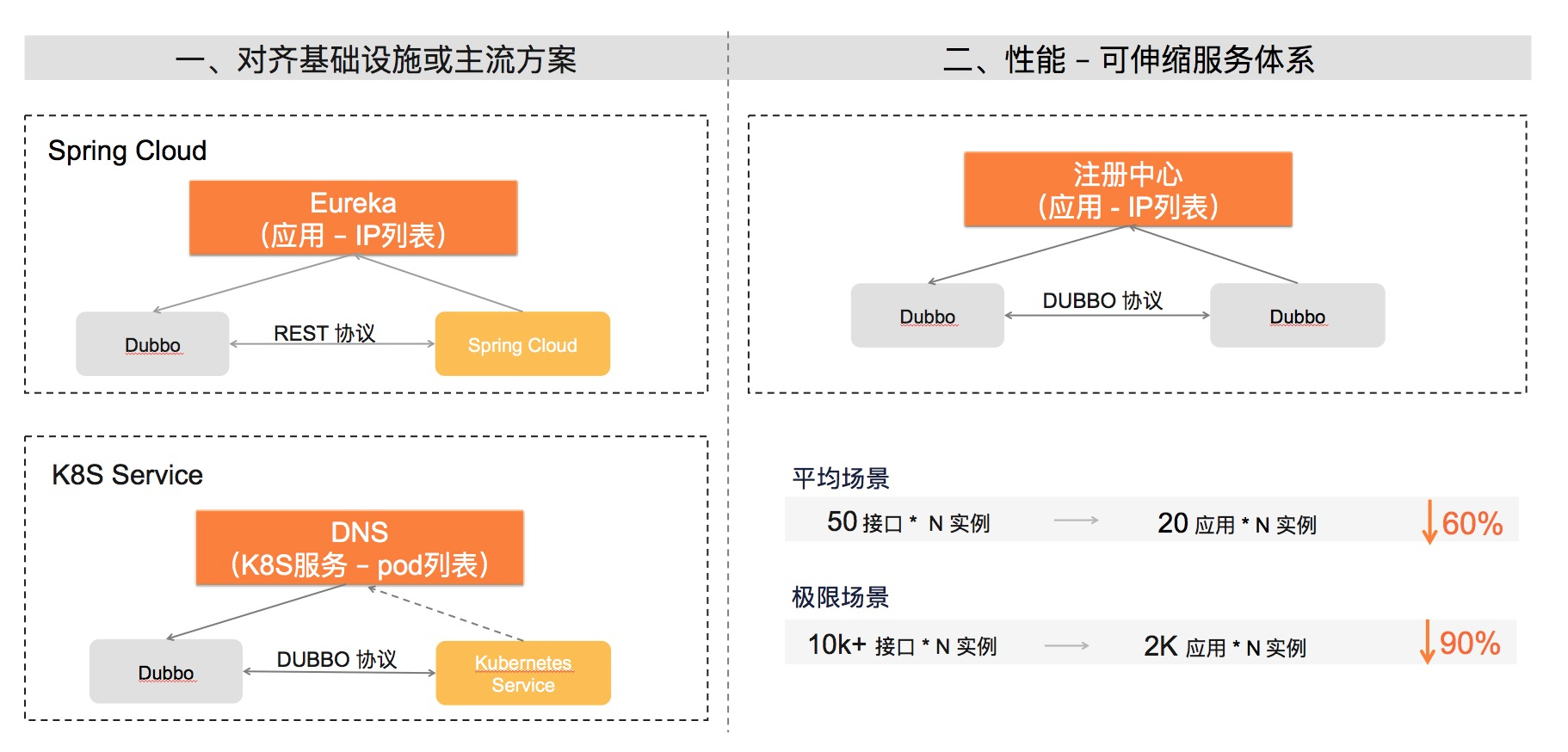
对齐主流微服务模型
Spring Cloud
Spring Cloud 通过注册中心只同步了应用与实例地址,消费方可以基于实例地址与服务提供方建立连接,但是消费方对于如何发起 HTTP 调用一无所知。
RPC 服务这部分信息目前都是通过线下约定或离线的管理系统来协商的,这种架构的优缺点总结如下
- 优势:部署结构清晰、地址推送量小
- 缺点:地址订阅需要指定应用名, provider 应用变更(拆分)需消费端感知;RPC 调用无法全自动同步

Dubbo
Dubbo 通过注册中心同时同步了实例地址和 RPC 方法,因此其能实现 RPC 过程的自动同步,面向 RPC 编程、面向 RPC 治理,对后端应用的拆分消费端无感知,其缺点则是地址推送数量变大,和 RPC 方法成正比。
更大规模的微服务集群 - 解决性能瓶颈
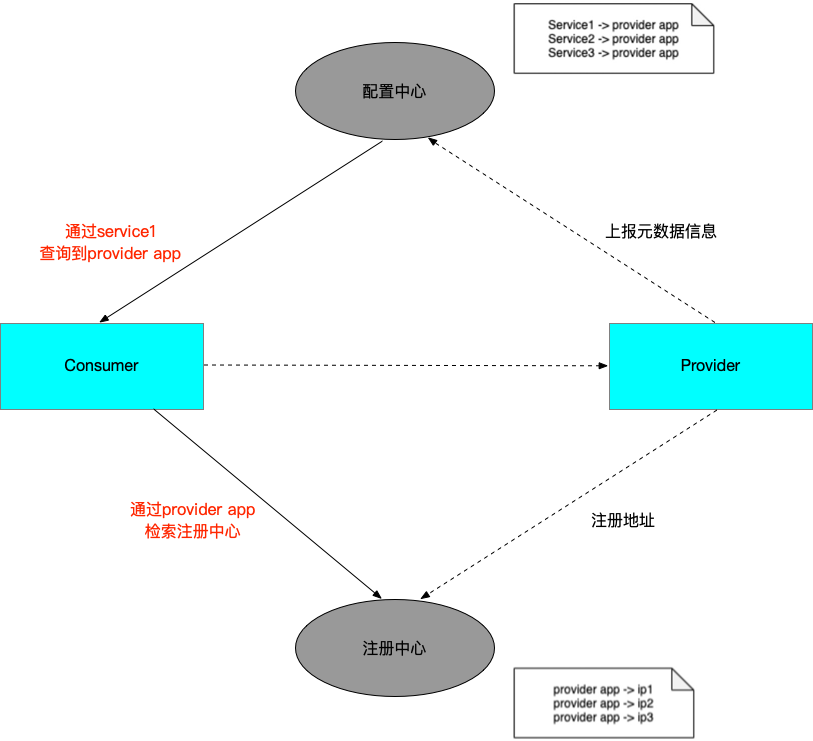
这部分涉及到和注册中心、配置中心的交互,关于不同模型下注册中心数据的变化,为更直观的对比服务模型变更带来的推送效率提升,我们来通过一个示例看一下不同模型注册中心的对比:
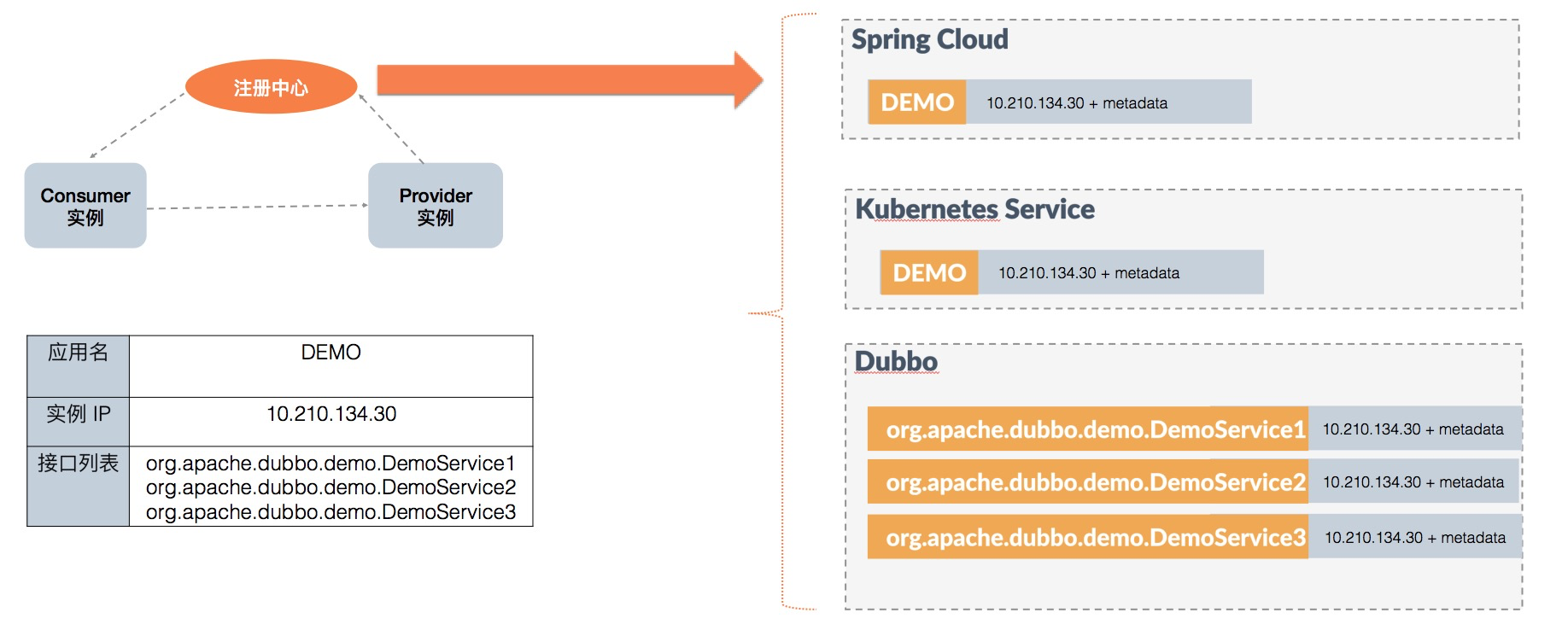
图中左边是微服务框架的一个典型工作流程,Provider 和 Consumer 通过注册中心实现自动化的地址通知。其中,Provider 实例的信息如图中表格所示: 应用 DEMO 包含三个接口 DemoService 1、DemoService 2、DemoService 3,当前实例的 ip 地址为 10.210.134.30。
- 对于 Spring Cloud 和 Kubernetes 模型,注册中心只会存储一条
DEMO - 10.210.134.30+metadata的数据 - 对于 Dubbo2 模型,注册中心存储了三条接口粒度的数据,分别对应三个接口 DemoService 1、DemoService 2、DemoService 3,并且很多的址数据都是重复的
可以总结出,基于应用粒度的模型所存储和推送的数据量是和应用、实例数成正比的,只有当我们的应用数增多或应用的实例数增长时,地址推送压力才会上涨。 而对于基于接口粒度的模型,数据量是和接口数量正相关的,鉴于一个应用通常发布多个接口的现状,这个数量级本身比应用粒度是要乘以倍数的;另外一个关键点在于, 接口粒度导致的集群规模评估的不透明,相对于实例、应用增长都通常是在运维侧的规划之中,接口的定义更多的是业务侧的内部行为,往往可以绕过评估给集群带来压力。
以 Consumer 端服务订阅举例,根据我对社区部分 Dubbo 中大规模头部用户的粗略统计,根据受统计公司的实际场景,一个 Consumer 应用要消费(订阅)的 Provier 应用数量往往要超过 10 个,而具体到其要消费(订阅)的的接口数量则通常要达到 30 个,平均情况下 Consumer 订阅的 3 个接口来自同一个 Provider 应用, 如此计算下来,如果以应用粒度为地址通知和选址基本单位,则平均地址推送和计算量将下降 60% 还要多, 而在极端情况下,也就是当 Consumer 端消费的接口更多的来自同一个应用时,这个地址推送与内存消耗的占用将会进一步得到降低,甚至可以超过 80% 以上。
一个典型的极端场景即是 Dubbo 体系中的网关型应用,有些网关应用消费(订阅)达 100+ 应用,而消费(订阅)的服务有 1000+ ,平均有 10 个接口来自同一个应用, 如果我们把地址推送和计算的粒度改为应用,则地址推送量从原来的 n * 1000 变为 n * 100,地址数量降低可达近 90%。
应用级服务发现的设计原则
以下是我们认为做应用级服务发现的设计原则:
- 新的服务发现模型要实现对原有 Dubbo 消费端开发者的无感知迁移,即 Dubbo 继续面向 RPC 服务编程、面向 RPC 服务治理,做到对用户侧完全无感知。可参见《地址发现迁移指南》
- 建立 Consumer 与 Provider 间的自动化 RPC 服务元数据协调机制,解决传统微服务模型无法同步 RPC 级接口配置的缺点
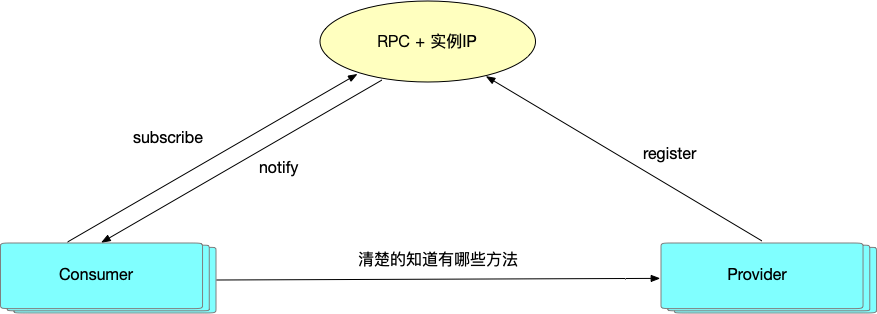
应用级服务发现作为一种新的服务发现机制,和以前 Dubbo2 基于 RPC 服务粒度的服务发现在核心流程上基本上是一致的:即服务提供者往注册中心注册地址信息,服务消费者从注册中心拉取&订阅地址信息。
应用级服务发现的工作原理
什么是服务自省
服务自省乍一听比较高大上,但其实简单来说服务自省主要终于在应用级服务发现场景下实现接口到应用、应用到接口的映射关系。 在注册中心不再同步 RPC 服务信息后,服务自省在服务消费端和提供端之间建立了一条内置的 RPC 服务信息协商机制,这也是"服务自省"这个名字的由来。 服务端实例会暴露一个预定义的 MetadataService RPC 服务,消费端通过调用 MetadataService 获取每个实例 RPC 方法相关的配置信息。

服务自省的工作流程
以下是服务自省的一个完整工作流程图,详细描述了服务注册、服务发现、MetadataService、RPC 调用间的协作流程。
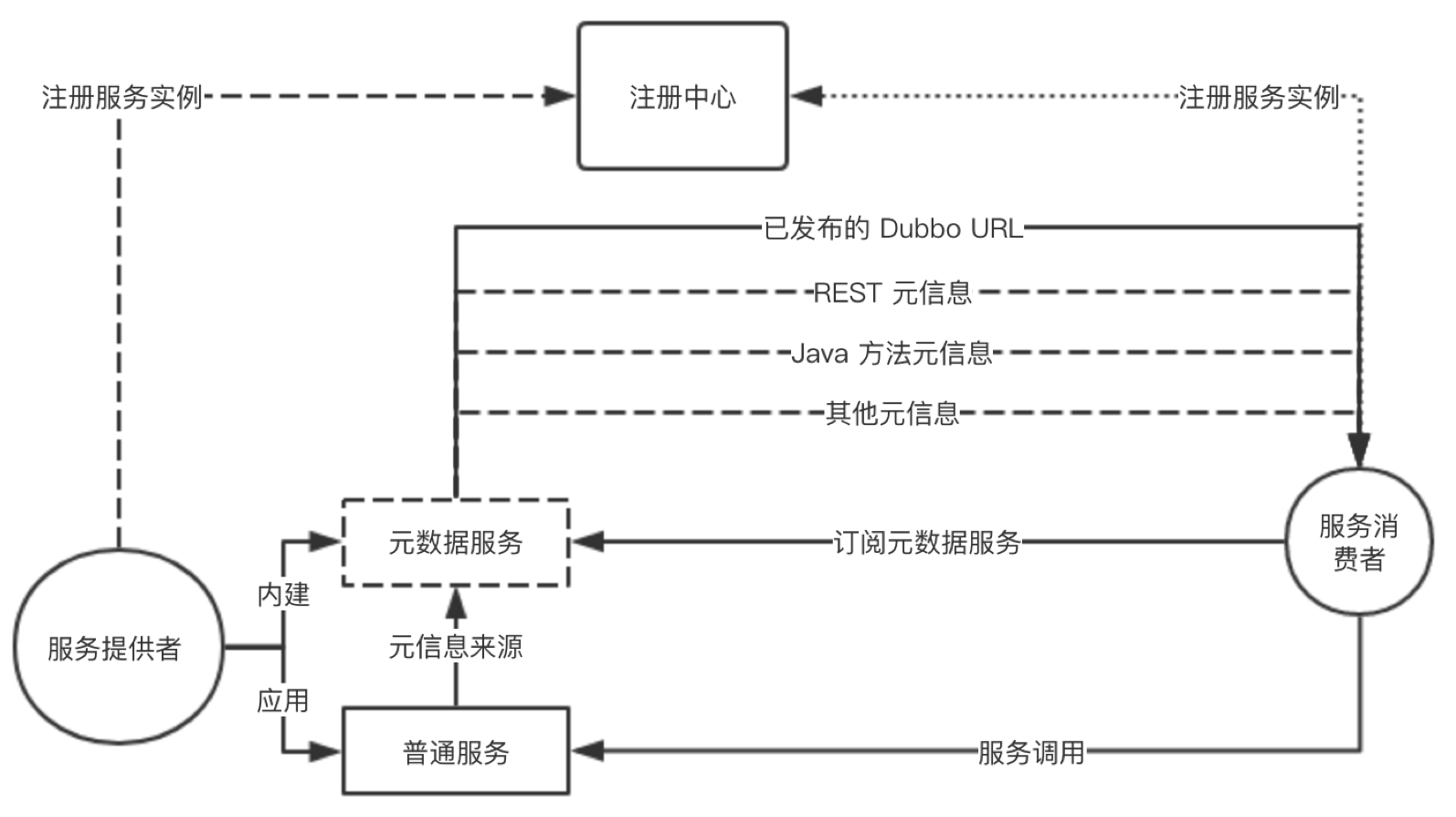
注册中心不再包含RPC信息
应用服务发现模型强调注册中心不再包含 RPC 信息,以"应用 - 实例列表"来组织,metadata 只包含当前 instance 节点相关的信息,不涉及 RPC 服务粒度的信息。 总体信息概括如下:实例地址、实例各种环境标、metadata service 元数据、其他少量必要属性。
元数据同步机制
- 内建 MetadataService
MetadataService 通过标准的 Dubbo 协议暴露,根据查询条件,会将内存中符合条件的“普通服务”配置返回给消费者。这一步发生在消费端选址和调用前。
- 元数据中心
复用 2.7 版本中引入的元数据中心,provider 实例启动后,会尝试将内部的 RPC 服务组织成元数据的格式到元数据中心,而 consumer 则在每次收到注册中心推送更新后,主动查询元数据中心。 注意 consumer 端查询元数据中心的时机,是等到注册中心的地址更新通知之后。也就是通过注册中心下发的数据,我们能明确的知道何时某个实例的元数据被更新了,此时才需要去查元数据中心。

构建 RPC 服务到应用名的映射关系
为了使整个开发流程对老的 Dubbo 用户更透明,同时避免指定 provider 对可扩展性带来的影响,我们设计了一套 RPC 服务到应用名的映射关系, 以尝试在 consumer 端自动完成 RPC 服务到 provider 应用名的转换。