服务发现
此文档已经不再维护。您当前查看的是快照版本。如果想要查看最新版本的文档,请参阅最新版本。
服务发现,即消费端自动发现服务地址列表的能力,是微服务框架需要具备的关键能力,借助于自动化的服务发现,微服务之间可以在无需感知对端部署位置与 IP 地址的情况下实现通信。
实现服务发现的方式有很多种,Dubbo 提供的是一种 Client-Based 的服务发现机制,通常还需要部署额外的第三方注册中心组件来协调服务发现过程,如常用的 Nacos、Consul、Zookeeper 等,Dubbo 自身也提供了对多种注册中心组件的对接,用户可以灵活选择。
Dubbo 基于消费端的自动服务发现能力,其基本工作原理如下图:
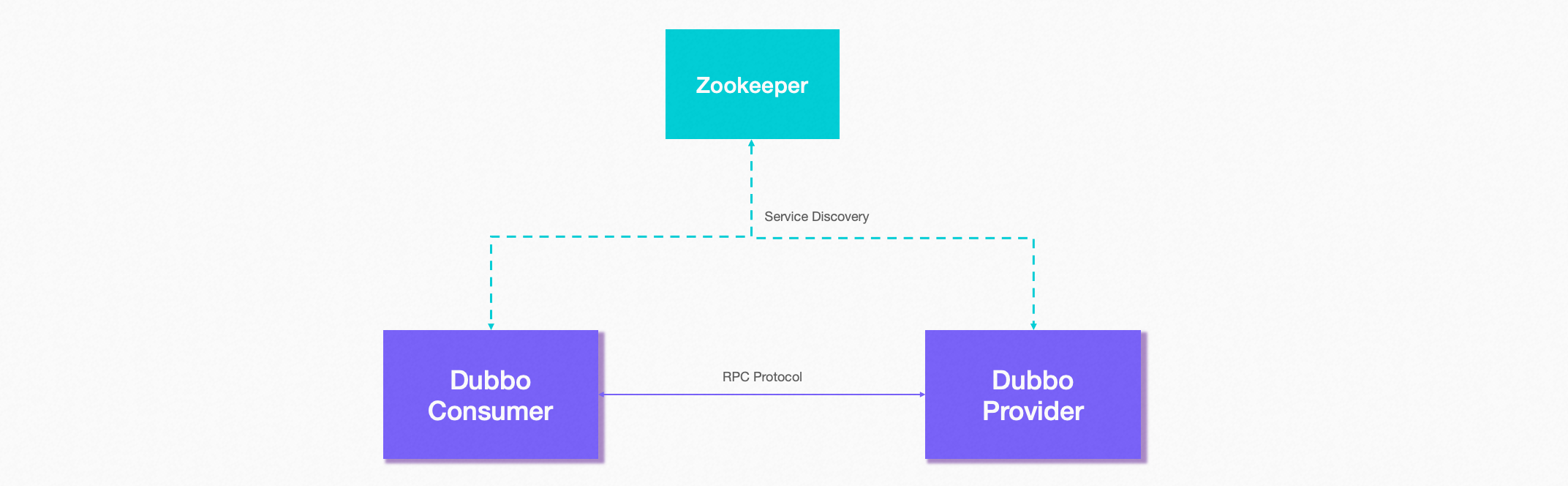
服务发现的一个核心组件是注册中心,Provider 注册地址到注册中心,Consumer 从注册中心读取和订阅 Provider 地址列表。 因此,要启用服务发现,需要为 Dubbo 增加注册中心配置:
以 dubbo-spring-boot-starter 使用方式为例,增加 registry 配置
# application.properties
dubbo
registry
address: zookeeper://127.0.0.1:2181
What’s New in Dubbo3
就使用方式上而言,Dubbo3 与 Dubbo2 的服务发现配置是完全一致的,不需要改动什么内容。但就实现原理上而言,Dubbo3 引入了全新的服务发现模型 - 应用级服务发现, 在工作原理、数据格式上已完全不能兼容老版本服务发现。
- Dubbo3 应用级服务发现,以应用粒度组织地址数据
- Dubbo2 接口级服务发现,以接口粒度组织地址数据
Dubbo3 格式的 Provider 地址不能被 Dubbo2 的 Consumer 识别到,反之 Dubbo2 的消费者也不能订阅到 Dubbo3 Provider。
- 对于新用户,我们提倡直接启用 Dubbo3 的默认行为,即启用应用级服务发现,参见《应用级服务发现》;
- 对于老用户,要面临如何平滑迁移到应用级服务发现的问题,考虑到老用户的规模如此之大,Dubbo3 默认保持了接口级地址发现的行为,这保证了老用户可以直接无感升级到 Dubbo3。 而如果要开启应用级服务发现,则需要通过配置显示开启(双注册、双订阅),具体开启与平滑迁移过程,可参见《地址发现迁移指南》。
应用级服务发现简介
概括来说,Dubbo3 引入的应用级服务发现主要有以下优势
- 适配云原生微服务变革。云原生时代的基础设施能力不断向上释放,像 Kubernetes 等平台都集成了微服务概念抽象,Dubbo3 的应用级服务发现是适配各种微服务体系的通用模型。
- 提升性能与可伸缩性。支持超大规模集群的服务治理一直以来都是 Dubbo 的优势,通过引入应用级服务发现模型,从本质上解决了注册中心地址数据的存储与推送压力,相应的 Consumer 侧的地址计算压力也成数量级下降;集群规模也开始变得可预测、可评估(与 RPC 接口数量无关,只与实例部署规模相关)。
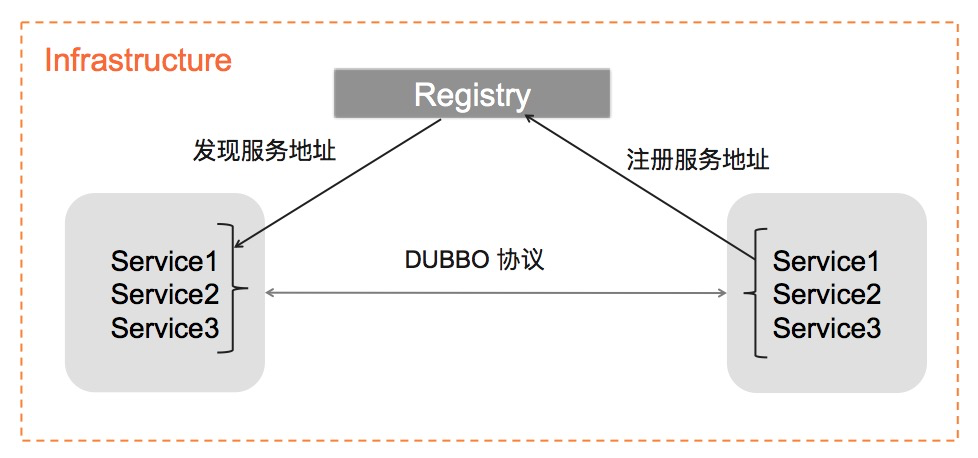
下图是 Dubbo2 的服务发现模型:Provider 注册服务地址,Consumer 经过注册中心协调并发现服务地址,进而对地址发起通信,这是被绝大多数微服务框架的经典服务发现流程。而 Dubbo2 的特殊之处在于,它把 “RPC 接口”的信息也融合在了地址发现过程中,而这部分信息往往是和具体的业务定义密切相关的。
而在接入云原生基础设施后,基础设施融入了微服务概念的抽象,容器化微服务被编排、调度的过程即完成了在基础设施层面的注册。如下图所示,基础设施既承担了注册中心的职责,又完成了服务注册的动作,而 “RPC 接口”这部分信息,由于与具体的业务相关,不可能也不适合被基础设施托管。
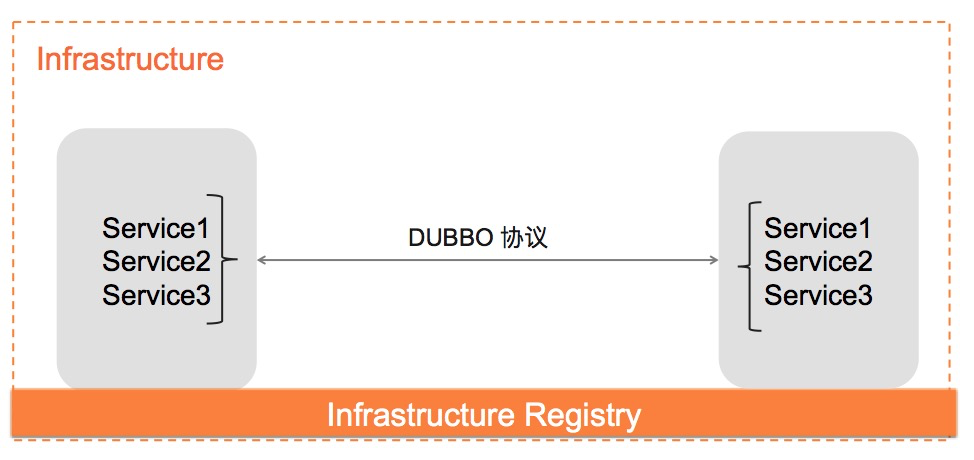
在这样的场景下,对 Dubbo3 的服务注册发现机制提出了两个要求: Dubbo3 需要在原有服务发现流程中抽象出通用的、与业务逻辑无关的地址映射模型,并确保这部分模型足够合理,以支持将地址的注册行为和存储委托给下层基础设施 Dubbo3 特有的业务接口同步机制,是 Dubbo3 需要保留的优势,需要在 Dubbo3 中定义的新地址模型之上,通过框架内的自有机制予以解决。
这样设计的全新的服务发现模型,在架构兼容性、可伸缩性上都给 Dubbo3 带来了更大的优势。
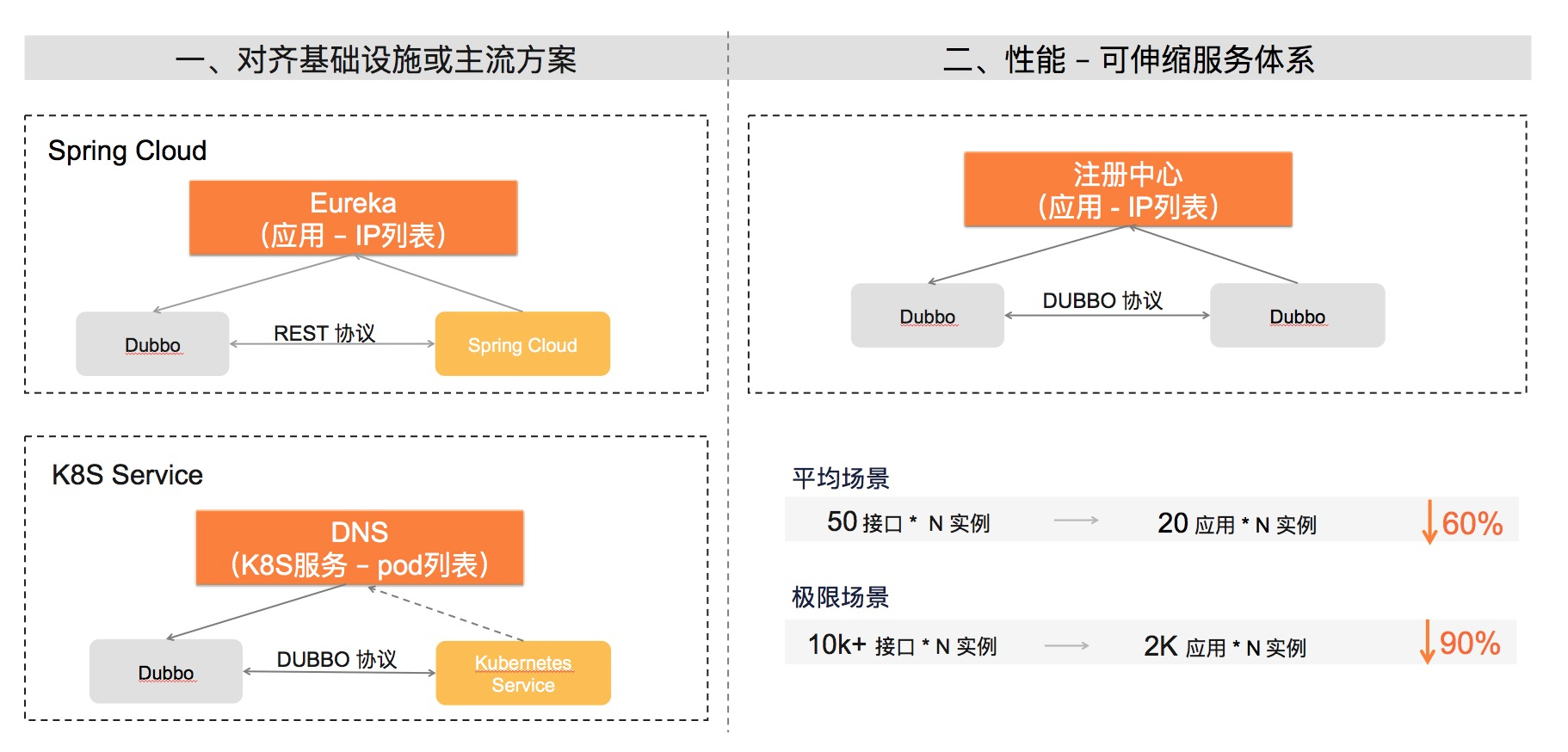
在架构兼容性上,如上文所述,Dubbo3 复用下层基础设施的服务抽象能力成为了可能;另一方面,如 Spring Cloud 等业界其它微服务解决方案也沿用这种模型, 在打通了地址发现之后,使得用户探索用 Dubbo 连接异构的微服务体系成为了一种可能。
Dubbo3 服务发现模型更适合构建可伸缩的服务体系,这点要如何理解? 这里先举个简单的例子,来直观的对比 Dubbo2 与 Dubbo3 在地址发现流程上的数据流量变化:假设一个微服务应用定义了 100 个接口(Dubbo 中的服务), 则需要往注册中心中注册 100 个服务,如果这个应用被部署在了 100 台机器上,那这 100 个服务总共会产生 100 * 100 = 10000 个虚拟节点;而同样的应用, 对于 Dubbo3 来说,新的注册发现模型只需要 1 个服务(只和应用有关和接口无关), 只注册和机器实例数相等的 1 * 100 = 100 个虚拟节点到注册中心。 在这个简单的示例中,Dubbo 所注册的地址数量下降到了原来的 1 / 100,对于注册中心、订阅方的存储压力都是一个极大的释放。更重要的是, 地址发现容量彻底与业务 RPC 定义解耦开来,整个集群的容量评估对运维来说将变得更加透明:部署多少台机器就会有多大负载,不会像 Dubbo2 一样, 因为业务 RPC 重构就会影响到整个集群服务发现的稳定性。