Metrics
概述
Dubbo Metrics 的总体设计请参考 可观测性 Metrics Proposal。
以下是 Dubbo Java 相关的具体实现与使用方式讲解。
使用方式
要为 Dubbo 进程开启指标采集,需要在项目中引入相关依赖并增加配置。以 Spring Boot 项目为例,增加以下 spring-boot-starter 依赖到项目中,即会自动开启指标采集。
<!-- https://mvnrepository.com/artifact/org.apache.dubbo/dubbo-metrics-prometheus -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-observability-starter</artifactId>
<version>3.2.0</version>
</dependency>
- 完整示例请参见 dubbo-samples-metrics-spring-boot
- 完整配置参数请参见 Metrics 配置项手册
实现原理解析
代码结构与工作流程
- 移除原来与 Metrics 相关的类
- 创建新模块 dubbo-metrics/dubbo-metrics-api、dubbo-metrics/dubbo-metrics-prometheus,MetricsConfig 作为该模块的配置类
- 使用micrometer,在Collector中使用基本类型代表指标,如Long、Double等,并在dubbo-metrics-api中引入micrometer,由micrometer对内部指标进行转换
以下是 Dubbo 实现中的关键组件及数据流转过程
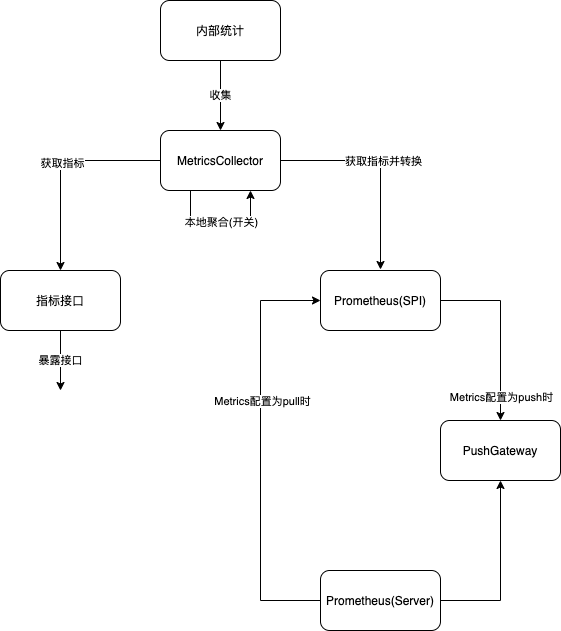
指标上报接口
根据上图架构,指标接口是 Dubbo 对外暴露指标数据的出口,以下是指标接口的具体定义:
另外,该 Service 还作为一些 智能自适应流量调度算法 的数据来源
public interface MetricsService {
/**
* Default {@link MetricsService} extension name.
*/
String DEFAULT_EXTENSION_NAME = "default";
/**
* The contract version of {@link MetricsService}, the future update must make sure compatible.
*/
String VERSION = "1.0.0";
/**
* Get metrics by prefixes
*
* @param categories categories
* @return metrics - key=MetricCategory value=MetricsEntityList
*/
Map<MetricsCategory, List<MetricsEntity>> getMetricsByCategories(List<MetricsCategory> categories);
/**
* Get metrics by interface and prefixes
*
* @param serviceUniqueName serviceUniqueName (eg.group/interfaceName:version)
* @param categories categories
* @return metrics - key=MetricCategory value=MetricsEntityList
*/
Map<MetricsCategory, List<MetricsEntity>> getMetricsByCategories(String serviceUniqueName, List<MetricsCategory> categories);
/**
* Get metrics by interface、method and prefixes
*
* @param serviceUniqueName serviceUniqueName (eg.group/interfaceName:version)
* @param methodName methodName
* @param parameterTypes method parameter types
* @param categories categories
* @return metrics - key=MetricCategory value=MetricsEntityList
*/
Map<MetricsCategory, List<MetricsEntity>> getMetricsByCategories(String serviceUniqueName, String methodName, Class<?>[] parameterTypes, List<MetricsCategory> categories);
}
其中 MetricsCategory 设计如下:
public enum MetricsCategory {
RT,
QPS,
REQUESTS,
}
MetricsEntity 设计如下
public class MetricsEntity {
private String name;
private Map<String, String> tags;
private MetricsCategory category;
private Object value;
}
指标采集埋点
Dubbo 是通过扩展 Filter SPI 扩展点实现对请求调用指标进行拦截的,目前在消费端和提供端分别增加了 Filter 扩展实现
- MetricsFilter 提供端请求指标埋点
- MetricsClusterFilter 消费端请求指标埋点
以下是 MetricsFilter 的实现源码,注意 try-catch-finally 处理。
@Activate(group = PROVIDER, order = -1)
public class MetricsFilter implements Filter, ScopeModelAware {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
collector.increaseTotalRequests(interfaceName, methodName, group, version);
collector.increaseProcessingRequests(interfaceName, methodName, group, version);
Long startTime = System.currentTimeMillis();
try {
Result invoke = invoker.invoke(invocation);
collector.increaseSucceedRequests(interfaceName, methodName, group, version);
return invoke;
} catch (RpcException e) {
collector.increaseFailedRequests(interfaceName, methodName, group, version);
throw e;
} finally {
Long endTime = System.currentTimeMillis();
Long rt = endTime - startTime;
collector.addRT(interfaceName, methodName, group, version, rt);
collector.decreaseProcessingRequests(interfaceName, methodName, group, version);
}
}
}
指标统计单位
以下五个属性是指标统计的基本单位(应用、服务、方法的组合),也是源代码 MetricsCollector 中 Map 数据结构的 key
public class MethodMetric {
private String applicationName;
private String interfaceName;
private String methodName;
private String group;
private String version;
}
基础指标
dubbo-common 模块下的 MetricsCollector 负责存储所有指标数据
public class DefaultMetricsCollector implements MetricsCollector {
private Boolean collectEnabled = false;
private final List<MetricsListener> listeners = new ArrayList<>();
private final ApplicationModel applicationModel;
private final String applicationName;
private final Map<MethodMetric, AtomicLong> totalRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> succeedRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> failedRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> processingRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> lastRT = new ConcurrentHashMap<>();
private final Map<MethodMetric, LongAccumulator> minRT = new ConcurrentHashMap<>();
private final Map<MethodMetric, LongAccumulator> maxRT = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> avgRT = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> totalRT = new ConcurrentHashMap<>();
private final Map<MethodMetric, AtomicLong> rtCount = new ConcurrentHashMap<>();
}
本地指标聚合
本地聚合指将一些简单的指标通过计算获取各分位数指标的过程。
开启本地聚合
收集指标时,默认只收集基础指标,而一些单机聚合指标则需要开启服务柔性或者本地聚合后另起线程计算。
dubbo.metrics.enable=true
另外,还可以设置一些更多的指标
dubbo.metrics.aggregation.enable=true
dubbo.metrics.aggregation.bucket-num=5
dubbo.metrics.aggregation.time-window-seconds=10
具体指标
具体指标 请参考 Dubbo Metrics 总体设计文档。
聚合收集器实现
public class AggregateMetricsCollector implements MetricsCollector, MetricsListener {
private int bucketNum;
private int timeWindowSeconds;
private final Map<MethodMetric, TimeWindowCounter> totalRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, TimeWindowCounter> succeedRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, TimeWindowCounter> failedRequests = new ConcurrentHashMap<>();
private final Map<MethodMetric, TimeWindowCounter> qps = new ConcurrentHashMap<>();
private final Map<MethodMetric, TimeWindowQuantile> rt = new ConcurrentHashMap<>();
private final ApplicationModel applicationModel;
private static final Integer DEFAULT_COMPRESSION = 100;
private static final Integer DEFAULT_BUCKET_NUM = 10;
private static final Integer DEFAULT_TIME_WINDOW_SECONDS = 120;
//在构造函数中解析配置信息
public AggregateMetricsCollector(ApplicationModel applicationModel) {
this.applicationModel = applicationModel;
ConfigManager configManager = applicationModel.getApplicationConfigManager();
MetricsConfig config = configManager.getMetrics().orElse(null);
if (config != null && config.getAggregation() != null && Boolean.TRUE.equals(config.getAggregation().getEnabled())) {
// only registered when aggregation is enabled.
registerListener();
AggregationConfig aggregation = config.getAggregation();
this.bucketNum = aggregation.getBucketNum() == null ? DEFAULT_BUCKET_NUM : aggregation.getBucketNum();
this.timeWindowSeconds = aggregation.getTimeWindowSeconds() == null ? DEFAULT_TIME_WINDOW_SECONDS : aggregation.getTimeWindowSeconds();
}
}
}
如果开启了本地聚合,则通过 spring 的 BeanFactory 添加监听,将 AggregateMetricsCollector 与 DefaultMetricsCollector 绑定,实现一种生存者消费者的模式,DefaultMetricsCollector 中使用监听器列表,方便扩展
private void registerListener() {
applicationModel.getBeanFactory().getBean(DefaultMetricsCollector.class).addListener(this);
}
指标聚合原理
滑动窗口
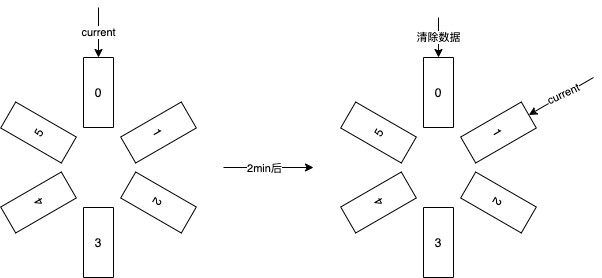
假设我们初始有6个bucket,每个窗口时间设置为2分钟
每次写入指标数据时,会将数据分别写入6个bucket内,每隔两分钟移动一个bucket并且清除原来bucket内的数据
读取指标时,读取当前current指向的bucket,以达到滑动窗口的效果
具体如下图所示,实现了当前 bucket 内存储了配置中设置的 bucket 生命周期内的数据,即近期数据
在每个bucket内,使用TDigest 算法计算分位数指标
TDigest 算法(极端分位精确度高,如p1 p99,中间分位精确度低,如p50),相关资料如下
- https://op8867555.github.io/posts/2018-04-09-tdigest.html
- https://blog.csdn.net/csdnnews/article/details/116246540
- 开源实现:https://github.com/tdunning/t-digest
代码实现如下,除了 TimeWindowQuantile 用来计算分位数指标外,另外提供了 TimeWindowCounter 来收集时间区间内的指标数量
public class TimeWindowQuantile {
private final double compression;
private final TDigest[] ringBuffer;
private int currentBucket;
private long lastRotateTimestampMillis;
private final long durationBetweenRotatesMillis;
public TimeWindowQuantile(double compression, int bucketNum, int timeWindowSeconds) {
this.compression = compression;
this.ringBuffer = new TDigest[bucketNum];
for (int i = 0; i < bucketNum; i++) {
this.ringBuffer[i] = TDigest.createDigest(compression);
}
this.currentBucket = 0;
this.lastRotateTimestampMillis = System.currentTimeMillis();
this.durationBetweenRotatesMillis = TimeUnit.SECONDS.toMillis(timeWindowSeconds) / bucketNum;
}
public synchronized double quantile(double q) {
TDigest currentBucket = rotate();
return currentBucket.quantile(q);
}
public synchronized void add(double value) {
rotate();
for (TDigest bucket : ringBuffer) {
bucket.add(value);
}
}
private TDigest rotate() {
long timeSinceLastRotateMillis = System.currentTimeMillis() - lastRotateTimestampMillis;
while (timeSinceLastRotateMillis > durationBetweenRotatesMillis) {
ringBuffer[currentBucket] = TDigest.createDigest(compression);
if (++currentBucket >= ringBuffer.length) {
currentBucket = 0;
}
timeSinceLastRotateMillis -= durationBetweenRotatesMillis;
lastRotateTimestampMillis += durationBetweenRotatesMillis;
}
return ringBuffer[currentBucket];
}
}
指标推送
指标推送只有用户在设置了 dubbo.metrics.protocol=prometheus 参数后才开启,若只开启指标聚合,则默认不推送指标。
Prometheus Pull Service Discovery
目前 Dubbo Admin 内置了 prometheus http_sd service discovery 实例地址发现机制,Admin 默认会使用 qos 端口、 /metrics 作为这样 Admin 就能够将所有示例地址汇聚后以标准 http_sd 的方式同步给 Prometheus Server。
具体配置方式如下
其中,address、port、url 均是可选项,如不配置则 Admin 使用默认约定值。
用户直接在Dubbo配置文件中配置Prometheus Pushgateway的地址即可,如<dubbo:metrics protocol=“prometheus” mode=“push” address="${prometheus.pushgateway-url}" interval=“5” />,其中interval代表推送间隔