扩展点开发指南
1. Dubbo SPI 扩展简介
Dubbo 中的扩展机制与 JDK 标准的 SPI 扩展点 原理类似。Dubbo 对其做了一定的改造与加强:
- JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
- 如果扩展点加载失败,JDK SPI 没给出详细信息,不方便定位问题,Dubbo SPI 在失败时记录真正的失败原因,并打印出来
- 增加 IOC、AOP 能力
- 增加排序能力
- 增加条件激活能力
- 提供了一系列更灵活的 API,如
获取所有 SPI 扩展实现、根据名称查询某个扩展实现、根据类型查询扩展实现、查询匹配条件的扩展实现等。
1.1 SPI定义
Dubbo 中的 SPI 插件是标准的 Java Interface 定义,并且必须包含 @org.apache.dubbo.common.extension.SPI 注解:
@SPI(value = "dubbo", scope = ExtensionScope.FRAMEWORK)
public interface Protocol {
// ...
}
@SPI 注解的定义如下:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
/**
* default extension name
*/
String value() default "";
/**
* scope of SPI, default value is application scope.
*/
ExtensionScope scope() default ExtensionScope.APPLICATION;
}
1.2 SPI加载流程
Dubbo 加载扩展的整个流程如下:
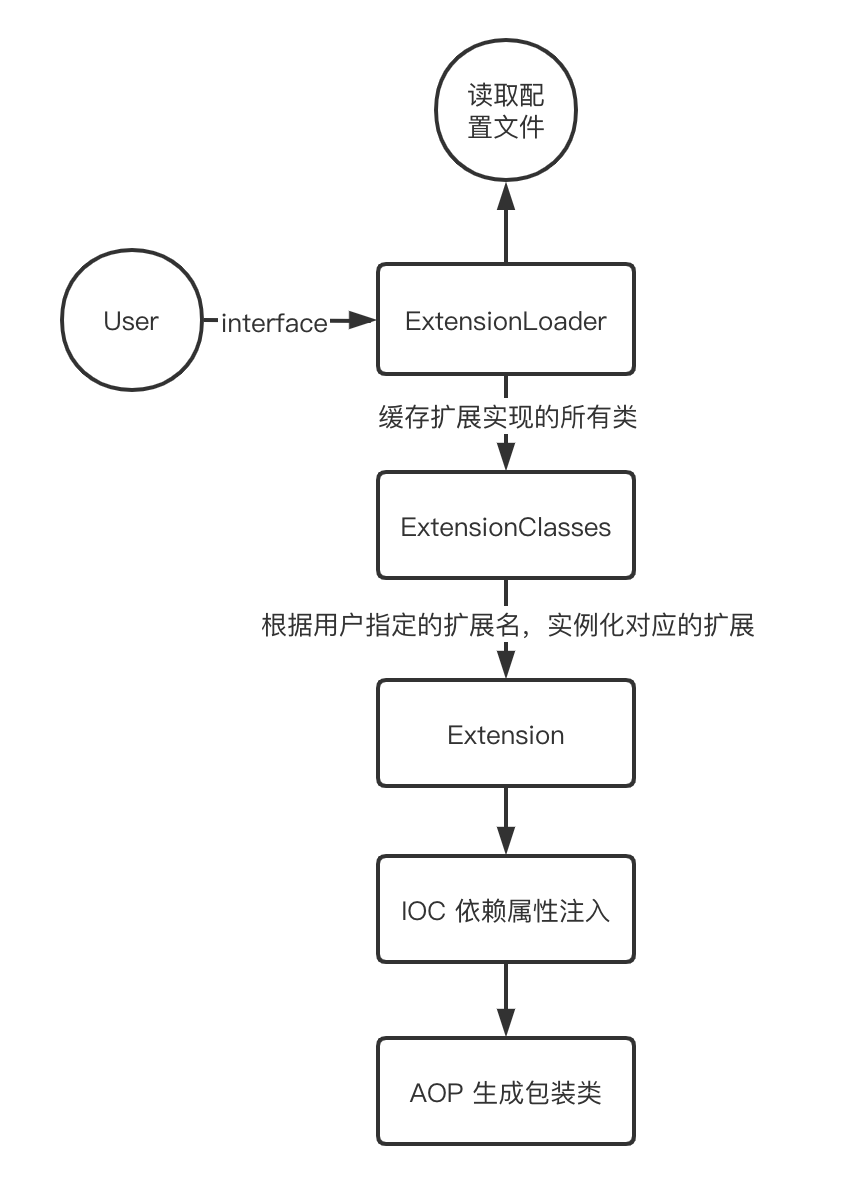
主要步骤为 4 个:
- 读取并解析配置文件
- 缓存所有扩展实现
- 基于用户执行的扩展名,实例化对应的扩展实现
- 进行扩展实例属性的 IOC 注入以及实例化扩展的包装类,实现 AOP 特性
2. Dubbo SPI 源码分析
2.1 按名称获取指定扩展类
Dubbo 中,SPI 加载固定扩展类的入口是 ExtensionLoader 的 getExtension 方法,下面我们对拓展类对象的获取过程进行详细的分析。
public T getExtension(String name) {
if (name == null || name.length() == 0)
throw new IllegalArgumentException("Extension name == null");
if ("true".equals(name)) {
// 获取默认的拓展实现类
return getDefaultExtension();
}
// Holder,顾名思义,用于持有目标对象
Holder<Object> holder = cachedInstances.get(name);
// 这段逻辑保证了只有一个线程能够创建 Holder 对象
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
// 双重检查
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
// 创建拓展实例
instance = createExtension(name);
// 设置实例到 holder 中
holder.set(instance);
}
}
}
return (T) instance;
}
上面代码的逻辑比较简单,首先检查缓存,缓存未命中则创建拓展对象。下面我们来看一下创建拓展对象的过程是怎样的。
private T createExtension(String name, boolean wrap) {
// 从配置文件中加载所有的拓展类,可得到“配置项名称”到“配置类”的映射关系表
Class<?> clazz = getExtensionClasses().get(name);
// 如果没有该接口的扩展,或者该接口的实现类不允许重复但实际上重复了,直接抛出异常
if (clazz == null || unacceptableExceptions.contains(name)) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
// 这段代码保证了扩展类只会被构造一次,也就是单例的.
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.getDeclaredConstructor().newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 向实例中注入依赖
injectExtension(instance);
// 如果启用包装的话,则自动为进行包装.
// 比如我基于 Protocol 定义了 DubboProtocol 的扩展,但实际上在 Dubbo 中不是直接使用的 DubboProtocol, 而是其包装类
// ProtocolListenerWrapper
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
// 循环创建 Wrapper 实例
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
if (wrapper == null
|| (ArrayUtils.contains(wrapper.matches(), name) && !ArrayUtils.contains(wrapper.mismatches(), name))) {
// 将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。
// 然后向 Wrapper 实例中注入依赖,最后将 Wrapper 实例再次赋值给 instance 变量
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
}
}
// 初始化
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}
createExtension 方法的逻辑稍复杂一下,包含了如下的步骤:
- 通过 getExtensionClasses 获取所有的拓展类
- 通过反射创建拓展对象
- 向拓展对象中注入依赖
- 将拓展对象包裹在相应的 Wrapper 对象中
- 初始化拓展对象
以上步骤中,第一个步骤是加载拓展类的关键,第三和第四个步骤是 Dubbo IOC 与 AOP 的具体实现。在接下来的章节中,将会重点分析 getExtensionClasses 方法的逻辑,以及简单介绍 Dubbo IOC 的具体实现。
2.1.1 获取所有拓展类
我们在通过名称获取拓展类之前,首先需要根据配置文件解析出拓展项名称到拓展类的映射关系表(Map<名称, 拓展类>),之后再根据拓展项名称从映射关系表中取出相应的拓展类即可。相关过程的代码分析如下:
private Map<String, Class<?>> getExtensionClasses() {
// 从缓存中获取已加载的拓展类
Map<String, Class<?>> classes = cachedClasses.get();
// 双重检查
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
// 加载拓展类
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
这里也是先检查缓存,若缓存未命中,则通过 synchronized 加锁。加锁后再次检查缓存,并判空。此时如果 classes 仍为 null,则通过 loadExtensionClasses 加载拓展类。下面分析 loadExtensionClasses 方法的逻辑。
private Map<String, Class<?>> loadExtensionClasses() {
// 缓存默认的 SPI 扩展名
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// 基于策略来加载指定文件夹下的文件
// 目前有四种策略,分别读取 META-INF/services/ META-INF/dubbo/ META-INF/dubbo/internal/ META-INF/dubbo/external/ 这四个目录下的配置文件
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}
return extensionClasses;
}
loadExtensionClasses 方法总共做了两件事情,一是对 SPI 注解进行解析,二是调用 loadDirectory 方法加载指定文件夹配置文件。SPI 注解解析过程比较简单,无需多说。下面我们来看一下 loadDirectory 做了哪些事情。
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type,
boolean extensionLoaderClassLoaderFirst, boolean overridden, String... excludedPackages) {
// fileName = 文件夹路径 + type 全限定名
String fileName = dir + type;
try {
Enumeration<java.net.URL> urls = null;
ClassLoader classLoader = findClassLoader();
// try to load from ExtensionLoader's ClassLoader first
if (extensionLoaderClassLoaderFirst) {
ClassLoader extensionLoaderClassLoader = ExtensionLoader.class.getClassLoader();
if (ClassLoader.getSystemClassLoader() != extensionLoaderClassLoader) {
urls = extensionLoaderClassLoader.getResources(fileName);
}
}
// 根据文件名加载所有的同名文件
if (urls == null || !urls.hasMoreElements()) {
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
// 加载资源
loadResource(extensionClasses, classLoader, resourceURL, overridden, excludedPackages);
}
}
} catch (Throwable t) {
logger.error("Exception occurred when loading extension class (interface: " +
type + ", description file: " + fileName + ").", t);
}
}
loadDirectory 方法先通过 classLoader 获取所有资源链接,然后再通过 loadResource 方法加载资源。我们继续跟下去,看一下 loadResource 方法的实现。
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader,
java.net.URL resourceURL, boolean overridden, String... excludedPackages) {
try {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8))) {
String line;
String clazz = null;
// 按行读取配置内容
while ((line = reader.readLine()) != null) {
// 定位 # 字符
final int ci = line.indexOf('#');
if (ci >= 0) {
// 截取 # 之前的字符串,# 之后的内容为注释,需要忽略
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
// 以等于号 = 为界,截取键与值
int i = line.indexOf('=');
if (i > 0) {
name = line.substring(0, i).trim();
clazz = line.substring(i + 1).trim();
} else {
clazz = line;
}
// 加载类,并通过 loadClass 方法对类进行缓存
if (StringUtils.isNotEmpty(clazz) && !isExcluded(clazz, excludedPackages)) {
loadClass(extensionClasses, resourceURL, Class.forName(clazz, true, classLoader), name, overridden);
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("Failed to load extension class (interface: " + type + ", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t);
exceptions.put(line, e);
}
}
}
}
} catch (Throwable t) {
logger.error("Exception occurred when loading extension class (interface: " +
type + ", class file: " + resourceURL + ") in " + resourceURL, t);
}
}
loadResource 方法用于读取和解析配置文件,并通过反射加载类,最后调用 loadClass 方法进行其他操作。loadClass 方法用于主要用于操作缓存,该方法的逻辑如下:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name,
boolean overridden) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred when loading extension class (interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + " is not subtype of interface.");
}
// 检测目标类上是否有 Adaptive 注解
if (clazz.isAnnotationPresent(Adaptive.class)) {
cacheAdaptiveClass(clazz, overridden);
} else if (isWrapperClass(clazz)) {
// 缓存包装类
cacheWrapperClass(clazz);
} else {
// 进入到这里,表明只是该类只是一个普通的拓展类
// 检测 clazz 是否有默认的构造方法,如果没有,则抛出异常
clazz.getConstructor();
if (StringUtils.isEmpty(name)) {
// 如果 name 为空,则尝试从 Extension 注解中获取 name,或使用小写的类名作为 name
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
// 如果类上有 Activate 注解,则使用 names 数组的第一个元素作为键,
// 存储 name 到 Activate 注解对象的映射关系
cacheActivateClass(clazz, names[0]);
for (String n : names) {
// 存储 Class 到名称的映射关系
cacheName(clazz, n);
// 存储 name 到 Class 的映射关系.
// 如果存在同一个扩展名对应多个实现类,基于 override 参数是否允许覆盖,如果不允许,则抛出异常.
saveInExtensionClass(extensionClasses, clazz, n, overridden);
}
}
}
}
如上,loadClass 方法操作了不同的缓存,比如 cachedAdaptiveClass、cachedWrapperClasses 和 cachedNames 等等。除此之外,该方法没有其他什么逻辑了。
到此,关于缓存类加载的过程就分析完了。整个过程没什么特别复杂的地方,大家按部就班的分析即可,不懂的地方可以调试一下。
2.2 加载自适应扩展类
先说明下自适应扩展类的使用场景。比如我们有需求,在调用某一个方法时,基于参数选择调用到不同的实现类,这和工厂方法有些类似,基于不同的参数,构造出不同的实例对象。在 Dubbo 中实现的思路和这个差不多,不过 Dubbo 的实现更加灵活,它的实现和策略模式有些类似。每一种扩展类相当于一种策略,基于 URL 消息总线,将参数传递给 ExtensionLoader,通过 ExtensionLoader 基于参数加载对应的扩展类,实现运行时动态调用到目标实例上。
自适应扩展类的含义是说,基于参数,在运行时动态选择到具体的目标类,然后执行。
在 Dubbo 中,很多拓展都是通过 SPI 机制进行加载的,比如 Protocol、Cluster、LoadBalance 等。有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载。这听起来有些矛盾。拓展未被加载,那么拓展方法就无法被调用(静态方法除外)。拓展方法未被调用,拓展就无法被加载。对于这个矛盾的问题,Dubbo 通过自适应拓展机制很好的解决了。自适应拓展机制的实现逻辑比较复杂,首先 Dubbo 会为拓展接口生成具有代理功能的代码。然后通过 javassist 或 jdk 编译这段代码,得到 Class 类。最后再通过反射创建代理类,整个过程比较复杂。
加载自适应扩展类的入口是 ExtensionLoader 的 getAdaptiveExtension 方法。
public T getAdaptiveExtension() {
// 从缓存中获取自适应拓展
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
// 如果存在异常,则直接抛出
if (createAdaptiveInstanceError != null) {
throw new IllegalStateException("Failed to create adaptive instance: " +
createAdaptiveInstanceError.toString(),
createAdaptiveInstanceError);
}
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
// double check
if (instance == null) {
try {
// 创建自适应拓展
// 这里分为两种情况:一种是存在 Adaptive 类,另一个是需要生成 Adaptive 类
instance = createAdaptiveExtension();
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t);
}
}
}
}
return (T) instance;
}
getAdaptiveExtension 方法首先会检查缓存,缓存未命中,则调用 createAdaptiveExtension 方法创建自适应拓展。下面,我们看一下 createAdaptiveExtension 方法的代码。
private T createAdaptiveExtension() {
try {
// 获取自适应拓展类,并通过反射实例化
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
} catch (Exception e) {
throw new IllegalStateException("Can not create adaptive extension ...");
}
}
createAdaptiveExtension 方法的代码比较少,但却包含了三个逻辑,分别如下:
- 调用 getAdaptiveExtensionClass 方法获取自适应拓展 Class 对象
- 通过反射进行实例化
- 调用 injectExtension 方法向拓展实例中注入依赖
前两个逻辑比较好理解,第三个逻辑用于向自适应拓展对象中注入依赖。这个逻辑看似多余,但有存在的必要,这里简单说明一下。前面说过,Dubbo 中有两种类型的自适应拓展,一种是手工编码的,一种是自动生成的。手工编码的自适应拓展中可能存在着一些依赖,而自动生成的 Adaptive 拓展则不会依赖其他类。这里调用 injectExtension 方法的目的是为手工编码的自适应拓展注入依赖,这一点需要大家注意一下。关于 injectExtension 方法,前文已经分析过了,这里不再赘述。接下来,分析 getAdaptiveExtensionClass 方法的逻辑。
private Class<?> getAdaptiveExtensionClass() {
// 通过 SPI 获取所有的拓展类
getExtensionClasses();
// 检查缓存,若缓存不为空,则直接返回缓存
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
// 创建自适应拓展类
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
getAdaptiveExtensionClass 方法同样包含了三个逻辑,如下:
- 调用 getExtensionClasses 获取所有的拓展类
- 检查缓存,若缓存不为空,则返回缓存
- 若缓存为空,则调用 createAdaptiveExtensionClass 创建自适应拓展类
这三个逻辑看起来平淡无奇,似乎没有多讲的必要。但是这些平淡无奇的代码中隐藏了着一些细节,需要说明一下。首先从第一个逻辑说起,getExtensionClasses 这个方法用于获取某个接口的所有实现类。比如该方法可以获取 Protocol 接口的 DubboProtocol、HttpProtocol、InjvmProtocol 等实现类。在获取实现类的过程中,如果某个实现类被 Adaptive 注解修饰了,那么该类就会被赋值给 cachedAdaptiveClass 变量。此时,上面步骤中的第二步条件成立(缓存不为空),直接返回 cachedAdaptiveClass 即可。如果所有的实现类均未被 Adaptive 注解修饰,那么执行第三步逻辑,创建自适应拓展类。相关代码如下:
private Class<?> createAdaptiveExtensionClass() {
// 构建自适应拓展代码
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
ClassLoader classLoader = findClassLoader();
// 获取编译器实现类
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
// 编译代码,生成 Class
return compiler.compile(code, classLoader);
}
createAdaptiveExtensionClass 方法用于生成自适应拓展类,该方法首先会生成自适应拓展类的源码,然后通过 Compiler 实例(Dubbo 默认使用 javassist 作为编译器)编译源码,得到代理类 Class 实例。接下来,我们把重点放在代理类代码生成的逻辑上,其他逻辑大家自行分析。
2.2.1 自适应拓展类代码生成
AdaptiveClassCodeGenerator#generate 方法生成扩展类代码
public String generate() {
// 如果该接口中没有方法被 @Adaptive 注解修饰,直接抛出异常
if (!hasAdaptiveMethod()) {
throw new IllegalStateException("No adaptive method exist on extension " + type.getName() + ", refuse to create the adaptive class!");
}
StringBuilder code = new StringBuilder();
// 生成包名、import、方法等.
code.append(generatePackageInfo());
code.append(generateImports());
code.append(generateClassDeclaration());
Method[] methods = type.getMethods();
for (Method method : methods) {
code.append(generateMethod(method));
}
code.append("}");
if (logger.isDebugEnabled()) {
logger.debug(code.toString());
}
return code.toString();
}
2.2.2 生成方法
上面代码中,生成方法的逻辑是最关键的,我们详细分析下。
private String generateMethod(Method method) {
String methodReturnType = method.getReturnType().getCanonicalName();
String methodName = method.getName();
// 生成方法内容
String methodContent = generateMethodContent(method);
String methodArgs = generateMethodArguments(method);
String methodThrows = generateMethodThrows(method);
return String.format(CODE_METHOD_DECLARATION, methodReturnType, methodName, methodArgs, methodThrows, methodContent);
}
generateMethodContent 分析
private String generateMethodContent(Method method) {
// 该方法上必须有 @Adaptive 注解修饰
Adaptive adaptiveAnnotation = method.getAnnotation(Adaptive.class);
StringBuilder code = new StringBuilder(512);
if (adaptiveAnnotation == null) {
// 没有 @Adaptive 注解修饰,生成异常信息
return generateUnsupported(method);
} else {
// 获取 URL 在参数列表上的索引
int urlTypeIndex = getUrlTypeIndex(method);
if (urlTypeIndex != -1) {
// 如果参数列表上存在 URL,生成对 URL 进行空检查
code.append(generateUrlNullCheck(urlTypeIndex));
} else {
// 如果参数列表不存在 URL 类型的参数,那么就看参数列表上参数对象中是否包含 getUrl 方法
// 有的话,生成 URL 空检查
code.append(generateUrlAssignmentIndirectly(method));
}
// 解析 Adaptive 注解上的 value 属性
String[] value = getMethodAdaptiveValue(adaptiveAnnotation);
// 如果参数列表上有 Invocation 类型的参数,生成空检查并获取 methodName.
boolean hasInvocation = hasInvocationArgument(method);
code.append(generateInvocationArgumentNullCheck(method));
// 这段逻辑主要就是为了生成 extName(也就是扩展名)
// 分为多种情况:
// 1.defaultExtName 是否存在
// 2.参数中是否存在 invocation 类型参数
// 3.是否是为 protocol 生成代理
// 为什么要对 protocol 单独考虑了?因为 URL 中有获取 protocol 值的方法
code.append(generateExtNameAssignment(value, hasInvocation));
// check extName == null?
code.append(generateExtNameNullCheck(value));
// 生成获取扩展(使用 ExtensionLoader.getExtension 方法)
code.append(generateExtensionAssignment());
// 生成返回语句
code.append(generateReturnAndInvocation(method));
}
return code.toString();
}
上面那段逻辑主要做了如下几件事: 1.检查方法上是否 Adaptive 注解修饰 2.为方法生成代码的时候,参数列表上要有 URL(或参数对象中有 URL) 3.使用 ExtensionLoader.getExtension 获取扩展 4.执行对应的方法
2.2.3 附一个动态生成代码后的例子
package org.apache.dubbo.common.extension.adaptive;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class HasAdaptiveExt$Adaptive implements org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt {
public java.lang.String echo(org.apache.dubbo.common.URL arg0,
java.lang.String arg1) {
// URL 空校验
if (arg0 == null) {
throw new IllegalArgumentException("url == null");
}
org.apache.dubbo.common.URL url = arg0;
// 获取扩展名
String extName = url.getParameter("has.adaptive.ext", "adaptive");
// 扩展名空校验
if (extName == null) {
throw new IllegalStateException(
"Failed to get extension (org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt) name from url (" +
url.toString() + ") use keys([has.adaptive.ext])");
}
// 获取扩展
org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt extension = (org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt) ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt.class)
.getExtension(extName);
// 执行对应的方法
return extension.echo(arg0, arg1);
}
}
2.3 IOC 机制
Dubbo IOC 是通过 setter 方法注入依赖。Dubbo 首先会通过反射获取到实例的所有方法,然后再遍历方法列表,检测方法名是否具有 setter 方法特征。若有,则通过 ObjectFactory 获取依赖对象,最后通过反射调用 setter 方法将依赖设置到目标对象中。整个过程对应的代码如下:
private T injectExtension(T instance) {
if (objectFactory == null) {
return instance;
}
try {
// 遍历目标类的所有方法
for (Method method : instance.getClass().getMethods()) {
// 检测方法是否以 set 开头,且方法仅有一个参数,且方法访问级别为 public
if (!isSetter(method)) {
continue;
}
/**
* 检测是否有 DisableInject 注解修饰.
*/
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
/**
* 检测是否实现了ScopeModelAware、ExtensionAccessorAware类,如果实现则不注入
*/
if (method.getDeclaringClass() == ScopeModelAware.class) {
continue;
}
if (instance instanceof ScopeModelAware || instance instanceof ExtensionAccessorAware) {
if (ignoredInjectMethodsDesc.contains(ReflectUtils.getDesc(method))) {
continue;
}
}
// 基本类型不注入
Class<?> pt = method.getParameterTypes()[0];
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
// 获取属性名,比如 setName 方法对应属性名 name
String property = getSetterProperty(method);
// 从 ObjectFactory 中获取依赖对象
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
// 注入
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("Failed to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}
在上面代码中,objectFactory 变量的类型为 AdaptiveExtensionFactory,AdaptiveExtensionFactory 内部维护了一个 ExtensionFactory 列表,用于存储其他类型的 ExtensionFactory。Dubbo 目前提供了两种 ExtensionFactory,分别是 SpiExtensionFactory 和 SpringExtensionFactory。前者用于创建自适应的拓展,后者是用于从 Spring 的 IOC 容器中获取所需的拓展。这两个类的类的代码不是很复杂,这里就不一一分析了。
Dubbo IOC 目前仅支持 setter 方式注入,总的来说,逻辑比较简单易懂。
2.4 AOP 机制
Dubbo AOP 机制采用 wrapper 设计模式实现,要成为一个 AOP wrapper 类,必须同时满足以下几个条件:
- wrapper 类必须实现 SPI 接口,如以下示例中的
class QosProtocolWrapper implements Protocol - 构造器 constructor 必须包含一个相同的 SPI 参数,如以下示例中
QosProtocolWrapper(Protocol protocol) - wrapper 类必须和普通的 SPI 实现一样写入配置文件,如以下示例
resources/META-INF/dubbo/internal/org.apache.dubbo.rpc.Protocol
public class QosProtocolWrapper implements Protocol, ScopeModelAware {
private final Protocol protocol;
public QosProtocolWrapper(Protocol protocol) {
if (protocol == null) {
throw new IllegalArgumentException("protocol == null");
}
this.protocol = protocol;
}
}
写入配置文件 resources/META-INF/dubbo/internal/org.apache.dubbo.rpc.Protocol:
qos=org.apache.dubbo.qos.protocol.QosProtocolWrapper
在通过 getExtension(name) 尝试获取并加载 SPI 扩展实例时,Dubbo 框架会判断所有满足以上 3 个条件的 wrapper 类实现,并将 wrapper 类按顺序包在实例外面,从而达到 AOP 拦截的效果。
以下是 wrapper 判断与加载的实现逻辑,你还可以使用 @Wrapper 注解来控制 wrapper 类的激活条件:
private T createExtension(String name, boolean wrap) {
Class<?> clazz = getExtensionClasses().get(name);
T instance = (T) extensionInstances.get(clazz);
// ...
if (wrap) { // 如果调用方告知需要 AOP,即 wrap=true
List<Class<?>> wrapperClassesList = new ArrayList<>();
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
for (Class<?> wrapperClass : wrapperClassesList) {
// 通过 @Wrapper 注解判断当前 wrapper 类是否要生效
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
boolean match = (wrapper == null)
|| ((ArrayUtils.isEmpty(wrapper.matches())
|| ArrayUtils.contains(wrapper.matches(), name))
&& !ArrayUtils.contains(wrapper.mismatches(), name));
if (match) {
instance = injectExtension(
(T) wrapperClass.getConstructor(type).newInstance(instance));
instance = postProcessAfterInitialization(instance, name);
}
}
}
}
}
2.5 Activate激活条件
可以使用 @org.apache.dubbo.common.extension.Activate 来控制 SPI 扩展实现在什么场景下加载生效。相比于任何场景下都生效,能精确的控制扩展实现的生效条件会让实现变得更灵活。
以下是一些使用场景示例:
// 不加 @Activate 注解,getActivateExtension() 时不会加载,其他 getExtension() 方法仍可正常加载
public class MetricsProviderFilter implements Filter{}
// 不加任何参数,表示在 getActivateExtension() 时无条件自动返回
@Activate
public class MetricsProviderFilter implements Filter{}
// group 支持 consumer、provider 两个固定值,getActivateExtension() 调用加载扩展点时自动过滤
// provider 表示在提供者端会被加载;consumer 表示在消费者端会被加载
@Activate(group="provider")
public class MetricsProviderFilter implements Filter{}
// URL 参数中有 cache 这个 key 时,调用 getActivateExtension() 才会加载
@Activate(value="cache")
public class MetricsProviderFilter implements Filter{}
// URL 参数中有 cache 这个 key 并且值为 test 时,调用 getActivateExtension() 才会加载
@Activate(value="cache:test")
public class MetricsProviderFilter implements Filter{}
以下是 @Activate 注解的具体定义:
/**
* Activate. This annotation is useful for automatically activate certain extensions with the given criteria,
* for examples: <code>@Activate</code> can be used to load certain <code>Filter</code> extension when there are
* multiple implementations.
* <ol>
* <li>{@link Activate#group()} specifies group criteria. Framework SPI defines the valid group values.
* <li>{@link Activate#value()} specifies parameter key in {@link URL} criteria.
* </ol>
* SPI provider can call {@link ExtensionLoader#getActivateExtension(URL, String, String)} to find out all activated
* extensions with the given criteria.
*
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Activate {
/**
* Activate the current extension when one of the groups matches. The group passed into
* {@link ExtensionLoader#getActivateExtension(URL, String, String)} will be used for matching.
*
* @return group names to match
* @see ExtensionLoader#getActivateExtension(URL, String, String)
*/
String[] group() default {};
/**
* Activate the current extension when the specified keys appear in the URL's parameters.
* <p>
* For example, given <code>@Activate("cache, validation")</code>, the current extension will be return only when
* there's either <code>cache</code> or <code>validation</code> key appeared in the URL's parameters.
* </p>
*
* @return URL parameter keys
* @see ExtensionLoader#getActivateExtension(URL, String)
* @see ExtensionLoader#getActivateExtension(URL, String, String)
*/
String[] value() default {};
/**
* Absolute ordering info, optional
*
* Ascending order, smaller values will be in the front o the list.
*
* @return absolute ordering info
*/
int order() default 0;
/**
* Activate loadClass when the current extension when the specified className all match
* @return className names to all match
*/
String[] onClass() default {};
}
2.6 扩展点排序
排序同样使用 @Activate 注解设置,以下是使用示例,order 值越小加载优先级越高。
@Activate(order=100)
public class FilterImpl1 implements Filter{}
@Activate(order=200)
public class FilterImpl2 implements Filter{}
3. Dubbo SPI 扩展示例
3.1 加载固定扩展类
3.1.1 编写 SPI 接口及实现类
不管是 Java SPI,还是 Dubbo 中实现的 SPI,都需要编写接口。不过 Dubbo 中的接口需要被 @SPI 注解修饰。
@SPI
public interface DemoSpi {
void say();
}
public class DemoSpiImpl implements DemoSpi {
public void say() {
}
}
3.1.2 将实现类放在特定目录下
从上面的代码可知,dubbo 在加载扩展类的时候,会从四个目录中读取。我们在 META-INF/dubbo 目录下新建一个以 DemoSpi 接口名为文件名的文件,内容如下:
demoSpiImpl = com.xxx.xxx.DemoSpiImpl(为 DemoSpi 接口实现类的全类名)
3.1.3 使用
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<DemoSpi> extensionLoader =
ExtensionLoader.getExtensionLoader(DemoSpi.class);
DemoSpi dmeoSpi = extensionLoader.getExtension("demoSpiImpl");
optimusPrime.sayHello();
}
}
3.2 加载自适应扩展类
这个以 Protocol 为例进行说明
3.2.1 Protocol 接口(抽取部分核心方法)
@SPI("dubbo")
public interface Protocol {
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
}
public class DubboProtocol extends AbstractProtocol {
......
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
return protocolBindingRefer(type, url);
}
@Override
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
......
return exporter;
}
}
3.2.2 将实现类放在特定目录下
在 dubbo 中,该配置路径 META-INF/dubbo/internal/org.apache.dubbo.rpc.Protocol
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol
需要说明一点的是,在 dubbo 中,并不是直接使用 DubboProtocol 的,而是使用的是其包装类。
3.2.3 使用
public class DubboAdaptiveTest {
@Test
public void sayHello() throws Exception {
URL url = URL.valueOf("dubbo://localhost/test");
Protocol adaptiveProtocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
adaptiveProtocol.refer(type, url);
}
}