该文章内容发布已经超过一年,请注意检查文章中内容是否过时。
启动速度提升10倍:Apache Dubbo 静态化 GraalVM Native Image 深度解析
摘要:本文整理自杭州有赞科技有限公司中间件技术专家、Apache Dubbo PMC华钟明在 Community Over Code 2023 大会上的分享。本篇内容主要分为五个部分:
- 一、GraalVM 直面Java应用在云时代的挑战
- 二、Dubbo 享受 AOT 带来的技术红利
- 三、Dubbo Native Image 的实践和示例
- 四、Dubbo 集成 Native Image 的原理和思考
- 五、Dubbo 在 Native Image 技术的未来规划
一、GraalVM 直面Java应用在云时代的挑战
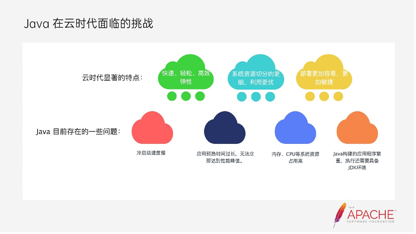
云计算时代比较显著的特点包括:
- 基于云计算的基础设施,Java应用能够在云计算的基础设施上快速、轻松、高效的做到弹性。
- 基于容器化技术,系统资源切分的更加细,资源的利用率也更高了。
- 基于云计算的开发平台,让应用部署的更加容易,更加敏捷。
那么在云计算时代,Java应用存在哪些问题呢?
- 冷启动速度较慢。
- 应用预热时间过长,无法立即达到性能峰值。
- 内存、CPU等系统资源占用高。
- Java构建的应用程序繁重,执行还需要具备JDK环境。

在Serverless场景上,Java的问题会尤为突出,因为Serverless不仅能简化开发场景和开发体验,还能做到极致的弹性,甚至是秒级的弹性。
上图是Datalog统计的Fast和AWS两个产品。Java语言虽然更流行,但相较于Python和Node.JS,它的占比还是比较低的。Java本身在Serverless层面,比如在做容器的调度、镜像的下载的时候,启动时间、冷启动的时间、预热时间等等,都会影响Serverless场景下它弹性扩容的时间。

下面介绍一下GraalVM,它是可以把Java应用提前编译到独立的二进制包内,这些二进制包相对于跑在JVM上它可以更小,更快的启动,不需要预热就能够达到极限的峰值,还可以减少内存和CPU的占比。
可以看到它的介绍和Java语言的应用所涉及到的问题都一一对应。GraalVM应该算是JDK的"超集",除了包含完整的JDK发行版本外,还有GraalVM Compiler、Native image、Truffle等,甚至还涉及到多语言汇编的能力。
总结一下,GraalVM本身涉及两部分,JIT和AOT。
- JIT,是在编译后的class文件、字节码文件,它会在运行时把它翻译成机器码。
- AOT, 它和JIT的区别是,它在编译期就能把字节码直接转化为机器码,无需在运行时再去处理。所以它的CPU和内存会相对更低。
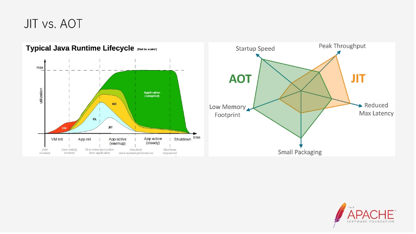
上图左侧是一张Java生命周期的全景图。可以看到,它从JVM的启动,再到Java的main函数的启动,再到Java的应用预热,再到它的稳定期,最后到达效果,这是Java完整的生命周期的呈现。
而AOT的区别在于,它没有红色的VM。另外,JIT相对于AOT而言是没有的,也没有浅绿色的解释器。所以AOT对于JIT来说,只有内加载,GC以及它能够瞬间达到应用的稳定期。
根据右侧的图可以看出:
- AOT的启动耗时相对较低,内存损耗和它打出来的二进制包相对较小。
- JIT因为有及时编译的效果,所以现在极限的分值比AOT要好,比如它的极限吞吐量比AOT好。
二、Dubbo 享受 AOT 带来的技术红利
- 多产物形态
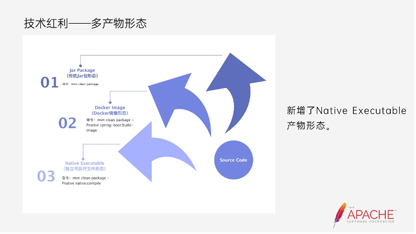
我们在编码之后,Soft Code的产物形态新增了。
第一种是我们传统认知上的Jar包形态,比如mvn、clean、package。第二种是Docker Image,它能轻松的帮我们直接打到镜像里面去,不用写dockerfile等文件。第三种是我们集成GraalVM后新产生的一种Native可执行文件的形态。这种形态无需JDK的环境就能启动,它能像GO一样把二进制文件直接启动。
- 启动耗时大幅降低
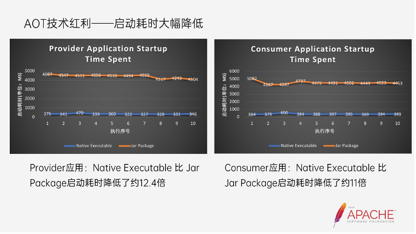
上图的跑分都是基于4c16g的micro24的系统上跑出来的。左边和右边的区别是,左边的Provider端提供了一个Dubbo服务跑出来的,右边是提供了一个调用者的身份跑分出来的。从左边这张图可以看到,Native的可视性文件比Jar包方式的启动耗时降低了12倍+,在客户端应用,它的启动耗时降低了11倍+。所以在刚刚提到的Serverless场景上,它能提供一个非常好的启动速度。在扩容的时候能够达到秒级,甚至达到毫秒级。
- 启动后立即达到性能峰值
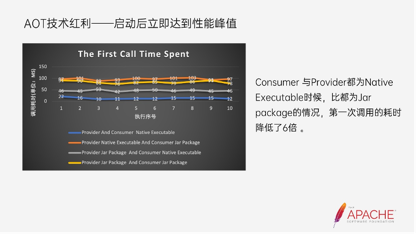
上图也是跑分跑出来的数据,可以看到Consumer和Provider端通过静态化执行文件执行后,比都为Jar包的情况,第一次调用的耗时降低6倍。这第一次调用代表的是预热的时长,以及第一次需要解析的类,包括资源的情况等等。这让我们在Serverless场景下能够瞬间达到性能峰值。
- 内存损耗大幅降低
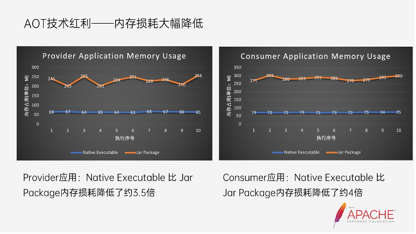
上面有左右两张图,在Dubbo应用的基础上,它的内存损耗也降低大概3.5倍。Native静态化执行文件可以做到60M的内存占比,在客户端它的内存损耗也大概降低了4倍。

这是Dubbo在Native Image技术场景中做的努力:
- 易用性增强:在注解和XML方式中自动识别服务接口,生成Reachability Metadata。
- 可维护性增强:自动生成Source code,减轻了Dubbo开发者维护Adaptive的维护成本。自动扫描生成Dubbo core 所需的Reachability Metadata。
- 多平台的支持:Linux、MacOS、Windows。
- 多功能的覆盖:Dubbo、Triple协议。
三、Dubbo Native Image 的实践和示例
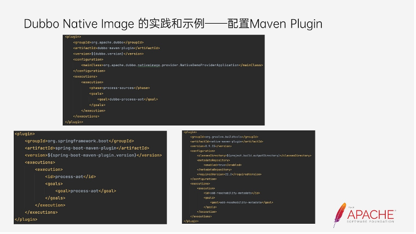
首先需要安装Dubbo Native Image,这里就不过多介绍了,大家可以根据官方的文档进行下载。
然后安装插件,可以看到上图中有三个插件需要安装,但和Dubbo相关的只有一个,是Dubbo Maven Plugin。除此之外,还有Spring Boot 的Maven Plugin,它提供的是Spring的AOT的能力。如果是API的接入方式我们无需加这个插件,如果是XML和注解就还需要加这个插件。第三个是GraalVM提供的插件,可以看到这里加了一个reachabilitu-metadata的执行,这个后面会介绍到。
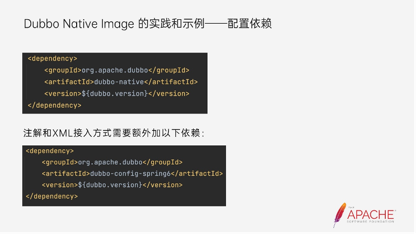
然后配置依赖,现在Dubbo关于可达性元数据的扫描、执行,以及配置文件和Source code的生成都在Dubbo Native的依赖下面,我们需要引入这个依赖。
另外,注解和XML的还是需要接入一个Spring6的兼容的包。因为Dubbo现在还兼容JDK 8的版本,而Spring6发布后支持的最低版本是JDK 17,所以我们还是需要有这么一个模块做一下兼容。
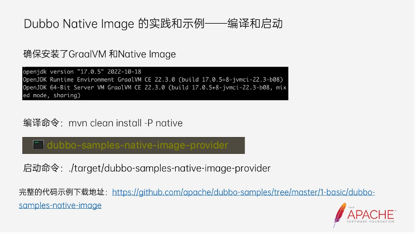
最后还需要加一个插件和依赖,然后就能轻松的把应用转化成Native Image的形式。
最下面是完整的代码示例,大家感兴趣的话,可以尝试一下编译打包,看一下执行的效果。
四、Dubbo 集成 Native Image 的原理和思考
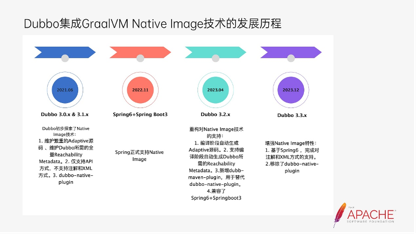
首先看一下Dubbo集成GraalVM Native Image技术的发展历程。2021年6月我们发布了Dubbo 3.0版本,初步探索了Native Image技术,提供了一个实验性的版本和Demo,涉及到的问题包括以下三个。
- 维护繁重的Adaptive源码、维护Dubbo所需的全量Reachability Metadata。可能涉及到的问题是,比如要新增一个功能,我们需要考虑coding以及code review的时候是否要添加可达性的元数据,这也会造成维护成本非常高。
- 仅支持API方式,不支持注解和XML方式。
- dubbo-native-plugin的插件,在后面3.1版本的时候,Native Image的发展并不多。
2022年11月Spring6+Spring Boot3正式发布了,它把Native Image技术作为发布的亮点展现给大家。但Dubbo社区认为我们应该对Native Image技术有一个新的跨越,所以在2023年4月发布了Dubbo 3.2版本,将Native Image技术进行了思考和重构。支持以下四个方面:
- 编译阶段自动生成Adaptive源码,已经不需要开发者维护了。
- 支持编译阶段自动生成Dubbo所需的Reachability Metadata。减小了打在业务启动的可执行文件里包的大小。因为在之前的版本里,它是把Dubbo所涉及的全量的可达性的元数据都打在二进制包里。比如业务用jka作为注册中心,我们把nacos也打在那里面,这就会导致它的二进制包非常大。现在这个版本如果用到jka,我们在box上解析不到nacos相关的依赖。所以我们就不会再把相关的内容打进去了,而且现在都是自动识别的。
- 新增dubbo-maven-plugin,用于替代dubbo-native-plugin。因为dubbo-native-plugin的能力和内容是比较聚焦的,我们把它重新归名为dubbo-maven-plugin后,涉及到的是我们能够降低业务接入的心智负担。后面Dubbo相关的maven插件,都通过它来做就行了。
- 兼容了Spring6+Spring Boot3,这就是我们在下个版本把XML和注解支持上去的技术的基础。
2023年12月将会发布Dubbo 3.3x版本。它基于Spring6,完成对XML和注解方式的支持,还移除了dubbo-native-plugin。

刚刚提到了非常多次Reachability Metadata可达性的元数据,到底是什么呢?
我们先来聊一聊AOT的局限性,它本身就有局限,它遵循封闭世界的一个假设。比如它只关注能看到的所有字节码的信息,这就会带来一个问题,Java动态语言的功能就不再支持了。也及时说JNI、Java反射、动态代理、ClassPath资源的获取等都不再支持。
我们知道,在组件/业务开发/使用产品上涉及到的这些功能是非常多的,既然GraalVM出了这个功能,当然也考虑到了这个问题,所以它利用Reachability Metadata的能力解决了这些问题。
右边的这张图分为了五类,它涉及到了JNI、反射、序列化、resource、proxy相关的元数据的配置信息。它可以让开发者在编译前就提供好这些元数据信息,提前打包到可执行的二进制文件中。还有第六种分类,是预定义的类型,他需要提供完整的字节码Hash值,所以就没列出来,它可能需要和Tracing的agent联合起来使用。
下面我们主要介绍一下这五类。
第一,GraalVM 提供了Tracing Agent来辅助应用采集Reachability Metadata,也就是说在运行期间它会去采集你的行为,比如你要用到反射,他会把反射的元素自动生成出来,然后生成出一个配置文件提供给你。但是并无法确保把所有都采集完整。
第二,GraalVM提供了Reachability Metadata Repository,用于管理三方组件的Reachability Metadata。我们在Java反射、动态代理这种纯业务的场景,用的相对较少,在运用到组件中相对多一点。举个例子,比如Native里用到反射,我们可以在仓库中直接找到Native反射的metadata。然后通过刚刚提到三个插件中的Native自身提供的插件,它会把仓库里的元数据直接打在二进制包里,我们也就不需要关心这些公共组件的元数据信息了。

和Dubbo相关的元数据信息包括以下五类:
第一,反射的元数据。
- 内外部的service。我们知道Dubbo是rpc框架,所以定义服务接口是最通用的一种能力。内部提供的服务包括metric service、metadata service,用户服务就是业务定义的服务接口。
- SPI扩展。Dubbo的扩展能力得益于自己建的一套SPI机制。
- 多实例。
- 配置相关的内容。
- 业务上自己用到的反射的行为。
第二,resource的元数据。如果业务上要做扩展,配置文件,resource的元数据主要涉及的就是META-INF下的三个路径。此外,还有一个是在Dubbo 3里支持对安全性的增强,序列化的黑白名单的resources的配置。
第三,序列化的元数据。作为rpc调用的框架,它的接口定义、方法定义、内外部分的服务、parameter、请求参数、返回类型等都需要用到序列化的接口。
第四,动态代理的元数据。在传统的rpc框架里动态代理是用的比较多的产品。内外部分服务的引用就是代理的元数据。
第五,JNI的元数据,暂时没有用到。

这是Dubbo 相关的 Reachability Metadata 总结和处理策略,我们把它分为了四类。
- 规律性的内容,是刚刚提到的Adaptive Source Code的生成。
- 确定性资源和行为,是Dubbo内部的扩展以及资源的配置。
- 不确定性的资源和行为,是业务自定义的扩展实现以及定义的服务。
- 集成和依赖的组件,比如刚刚提到jka是其他社区的生态,它涉及到注解的元数据信息,我们会提供官方的支持,还会提供内部的适配逻辑。
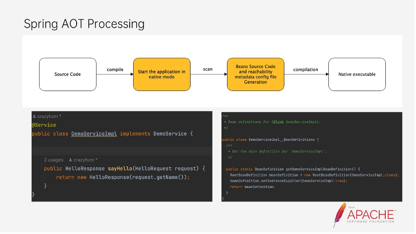
这是AOT的执行流程。可以看到它的源码在编译之后,它的区别是它会从main函数开始启动Java应用进程,然后去找所有的source code和Bean的元数据信息。
下面是Spring Server自动生成的一个source code,它会把它生成一个Bean定义的获取的类。
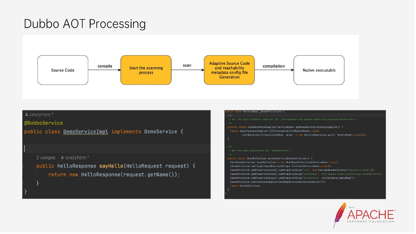
而Dubbo并不是从main函数启动的,它启动了一个扫描的进程,把确定性的、不确定性的元素以及规律性的内容扫描进来,自动帮大家生成元数据信息。
下面是用Dubbo service生成后的一些信息。
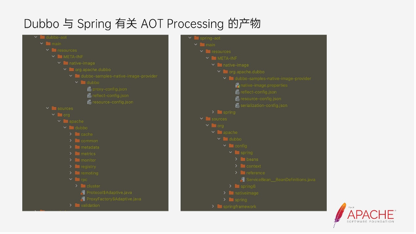
上图是Spring本身提供的一个产物的内容以及Dubbo的AOT产物的内容。可以看到Dubbo下面是Adaptive的一些source code。最后Native在执行的时候会读取到这里所有的配置。
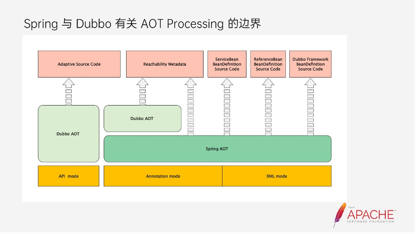
这是Dubbo和AOT之间的边界,可以看到API的接入方式和注解、XML的接入方式是有所区别的。注解和XML借用了Spring AOT的能力,包括ServiceBean、ReferenceBean等等,而Dubbo AOT的能力主要是自身的元数据的生产。
五、Dubbo 在 Native Image 技术的未来规划
- 提升开发者体验&开发效率
Dubbo在3.0之后提供了CTL、脚手架、IDEA插件,Dubbo Native Image目前还在建设中,之后也会加进去。此外,还有一些文档的建设。
- 性能优化与提升
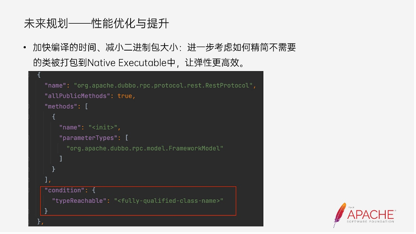
刚刚已经分享了很多内容,但还是有很多可以做的事情。在GraalVM提供的能力上,我们还可以把一些类相关的可达性的配置加上去,产生作用之后能让最后打出来的二进制包更小,编译时间更短。
- 覆盖更多的组件

因为目前很多组件都还不支持,所以我们现在的主要思路是把Dubbo主仓库的扩展性支持完成,然后再往wpi的扩展上做相应的支持。
另外,内核所需要的可达性的元数据,我们会把它推到program的可达性的元数据的仓库上面去,让业务开发能够正常使用大陆内核里的元数据信息。
最后我们的思路还是优先考虑GraalVM官方的支持。