Understanding Dubbo Core Concepts and Architecture
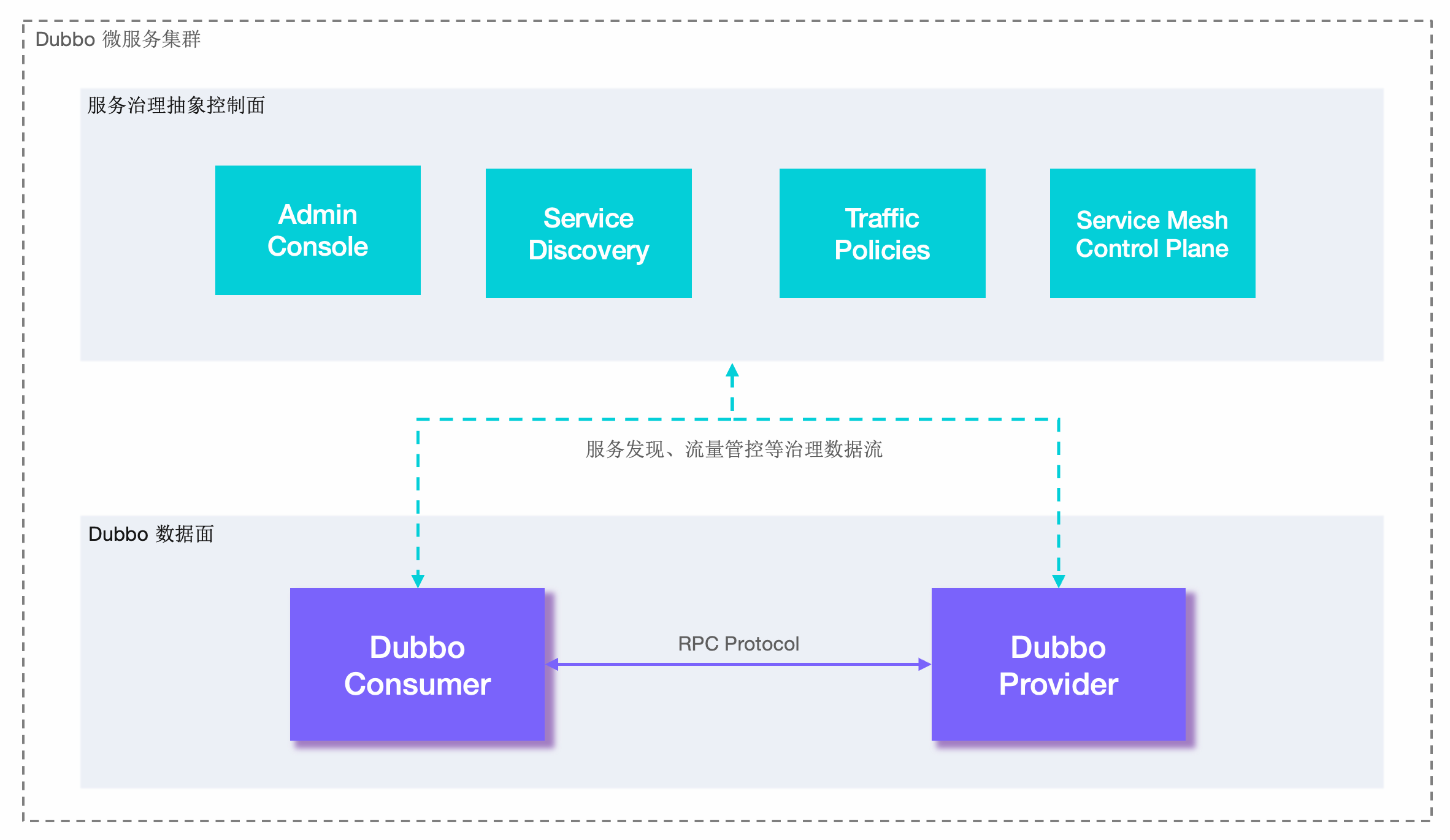
The above is a diagram of Dubbo’s working principle, which is divided into two layers from an abstract architecture perspective: Service Governance Abstract Control Plane and Dubbo Data Plane.
- Service Governance Control Plane. The service governance control plane does not specifically refer to a single component like a registry but is an abstract expression of the Dubbo governance system. The control plane includes the registry that coordinates service discovery, traffic control strategies, Dubbo Admin console, etc. If the Service Mesh architecture is adopted, it also includes service mesh control planes like Istio.
- Dubbo Data Plane. The data plane represents all Dubbo processes deployed in the cluster. These processes exchange data through the RPC protocol. Dubbo defines the development and invocation specifications for microservice applications and is responsible for the encoding and decoding of data transmission.
- Service Consumer (Dubbo Consumer), the Dubbo process that initiates business calls or RPC communication
- Service Provider (Dubbo Provider), the Dubbo process that receives business calls or RPC communication
Dubbo Data Plane
From the data plane perspective, Dubbo helps solve the following problems in microservice practices:
- Dubbo, as a service development framework, constrains the definition, development, and invocation specifications of microservices, defining service governance processes and adaptation patterns.
- Dubbo, as an RPC communication protocol implementation, solves the encoding and decoding issues of data transmission between services.
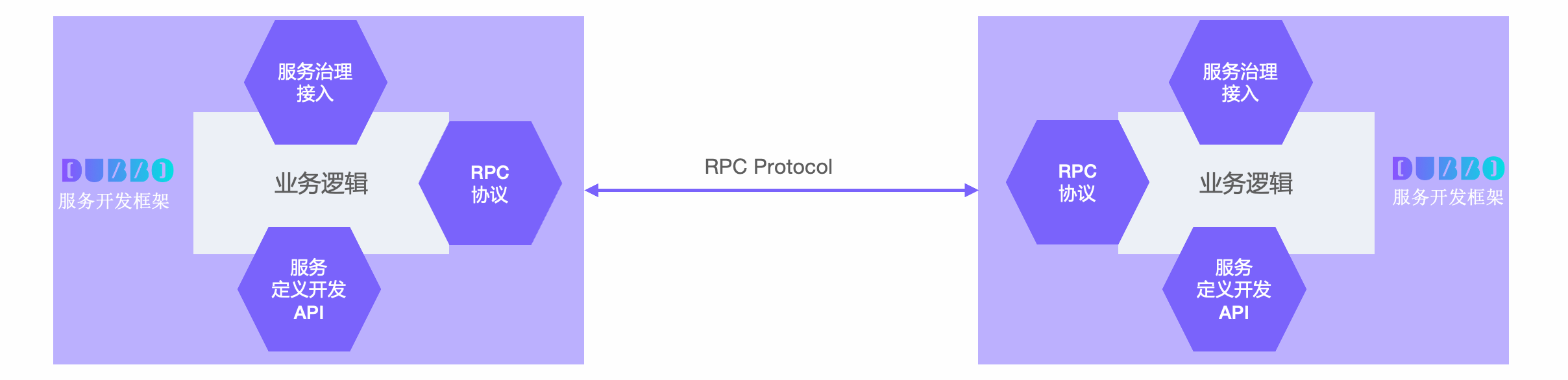
Service Development Framework
The goal of microservices is to build sufficiently small, self-contained, independently evolving, and deployable distributed applications that can run at any time. Almost every language has similar application development frameworks to help developers quickly build such microservice applications. For example, Spring Boot in the Java microservice ecosystem helps Java microservice developers quickly develop, package, deploy, and run applications with minimal configuration and in the most lightweight manner.
The distributed nature of microservices makes dependencies, network interactions, and data transmission between applications more frequent. Therefore, different applications need to define, expose, or invoke RPC services. How are these RPC services defined, how do they integrate with the application development framework, and how is service invocation controlled? This is the meaning of the Dubbo service development framework. Dubbo abstracts a set of RPC service definition, exposure, invocation, and governance programming paradigms on top of the microservice application development framework. For example, Dubbo Java, as a service development framework, is a microservice development framework built on the Spring Boot application development framework when running in the Spring ecosystem. It abstracts a set of RPC service definition, exposure, invocation, and governance programming paradigms on top of it.
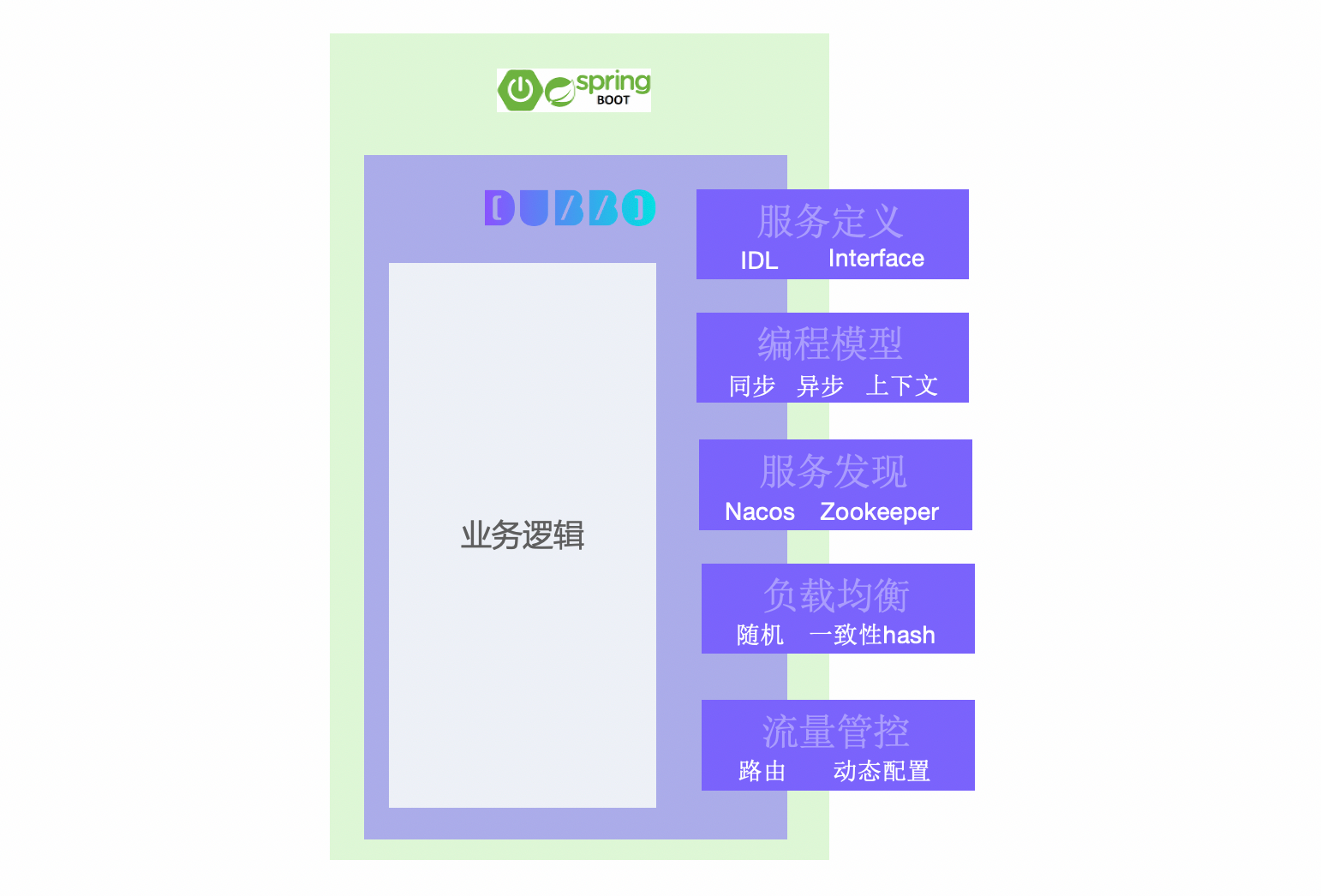
The specific contents included in Dubbo as a service development framework are as follows:
- RPC service definition and development paradigm. For example, Dubbo supports defining services through IDL and also supports service development definition methods specific to programming languages, such as defining services through Java Interface.
- RPC service publishing and invocation API. Dubbo supports synchronous, asynchronous, Reactive Streaming, and other service invocation programming models. It also supports request context API, setting timeout, etc.
- Service governance strategies, processes, and adaptation methods. As the data plane of the service framework, Dubbo defines service address discovery, load balancing strategies, rule-based traffic routing, Metrics collection, and other service governance abstractions, and adapts them to specific product implementations.
Want to know how to use the Dubbo microservice framework for business coding? Start your microservice project development journey with the following SDKs:
Communication Protocol
Dubbo is designed not to bind to any specific communication protocol. HTTP/2, REST, gRPC, JsonRPC, Thrift, Hessian2, and almost all mainstream communication protocols are supported by the Dubbo framework. This Protocol design pattern brings maximum flexibility to building microservices. Developers can choose different communication protocols based on needs such as performance and generality, without requiring any proxies for protocol conversion. You can even achieve protocol migration through Dubbo.
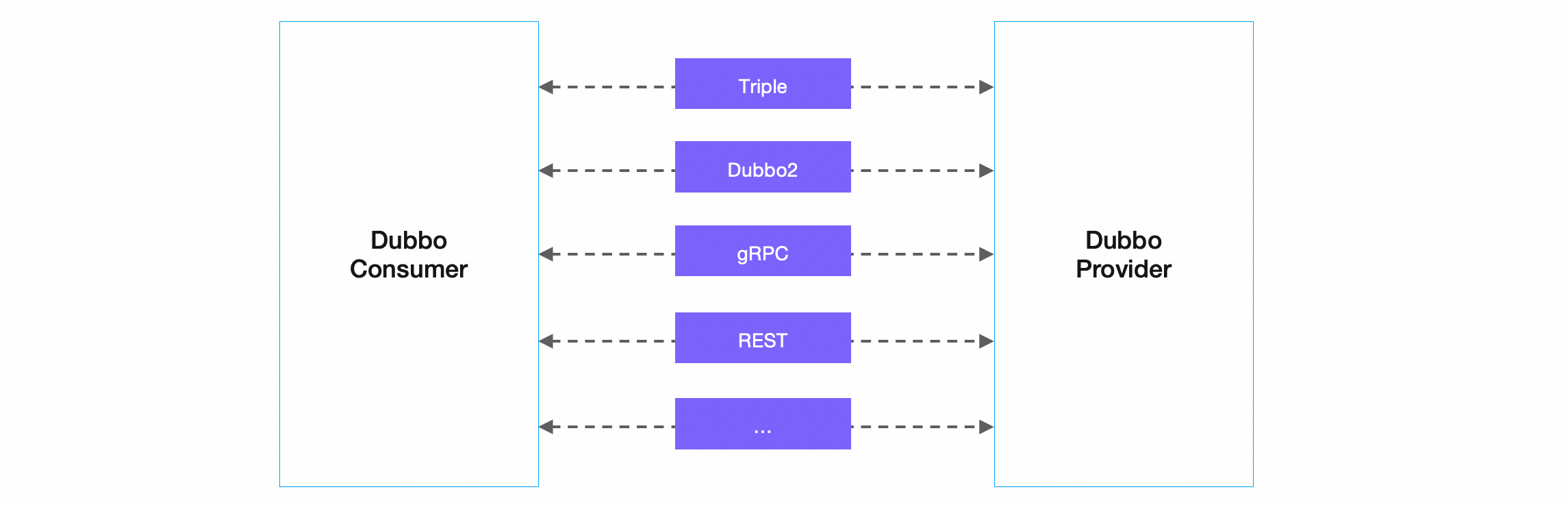
Dubbo Protocol is designed to support extensions, allowing you to adapt internal private protocols to the Dubbo framework, thereby integrating private protocols into the Dubbo system to enjoy Dubbo’s development experience and service governance capabilities. For example, Alibaba, a typical user of Dubbo3, achieved the overall migration from the internal HSF framework to the Dubbo3 framework by extending support for the HSF protocol.
Dubbo also supports multi-protocol exposure, allowing you to expose multiple protocols on a single port. The Dubbo Server can automatically recognize and ensure that requests are correctly processed. You can also publish the same RPC service on different ports (protocols) to serve callers from different technology stacks.
Dubbo provides two built-in high-performance protocol implementations, Dubbo2 and Triple (compatible with gRPC), to meet the high-performance communication needs of some microservice users. Both were initially designed and born in Alibaba’s internal high-performance communication business scenarios.
- The Dubbo2 protocol is a binary communication protocol designed on top of the TCP transport layer protocol.
- Triple is a streaming communication protocol built on top of HTTP/2, fully compatible with gRPC but optimized to better fit the Dubbo framework.
In summary, Dubbo’s support for communication protocols has the following characteristics:
- Not bound to a specific communication protocol
- Provides high-performance communication protocol implementations
- Supports streaming communication models
- Not bound to a specific serialization protocol
- Supports multi-protocol exposure for a single service
- Supports multi-protocol publishing on a single port
- Supports different communication protocols for multiple services within an application
Dubbo Service Governance
While a service development framework solves development and communication issues, in a microservice cluster environment, we still need to address a series of issues such as dynamic changes of stateless service nodes, externalized configuration, log tracing, observability, traffic management, high availability, and data consistency. We collectively refer to these issues as service governance.
Dubbo abstracts a set of microservice governance patterns and releases corresponding official implementations. Service governance helps simplify microservice development and operations, allowing developers to focus more on the microservice business itself.
Service Governance Abstraction
The following shows the core service governance functions defined by Dubbo
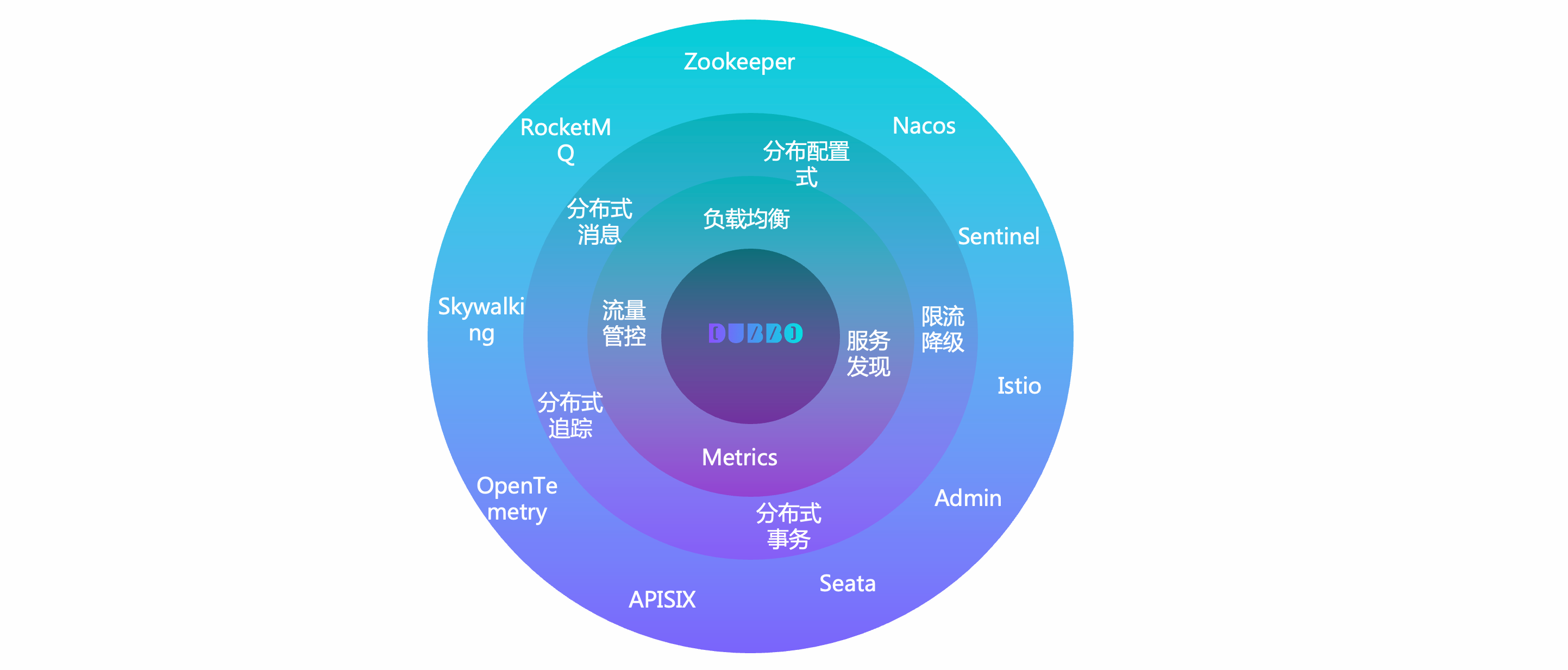
- Address Discovery
Dubbo service discovery has advantages such as high performance, support for large-scale clusters, and service-level metadata configuration. It provides multiple registry adapters by default, including Nacos, Zookeeper, Consul, etc., integrates with Spring Cloud and Kubernetes Service models, and supports custom extensions.
- Load Balancing
Dubbo provides default strategies such as weighted random, weighted round-robin, least active requests first, shortest response time first, consistent hashing, and adaptive load balancing.
- Traffic Routing
Dubbo supports controlling the distribution and behavior of service call traffic through a series of traffic rules. Based on these rules, capabilities such as weighted traffic distribution, gray verification, canary release, routing by request parameters, region priority, timeout configuration, retries, rate limiting, and degradation can be achieved.
- Link Tracing
Dubbo officially provides support for full-link tracing through adaptation to OpenTelemetry. Users can integrate products that support the OpenTelemetry standard, such as Skywalking and Zipkin. Additionally, many communities like Skywalking and Zipkin also provide adaptations for Dubbo.
- Observability
Dubbo instances report multi-dimensional observability metrics such as QPS, RT, request count, success rate, and exception count through Prometheus, helping to understand the service running status. By integrating with Grafana and the Admin console, data metrics can be visually displayed.
The Dubbo service governance ecosystem also provides adaptation support for scenarios such as API Gateway, Rate Limiting and Degradation, Data Consistency, and Authentication and Authorization.
Dubbo Admin
The Admin console provides a visual view of the Dubbo cluster. Through Admin, you can complete almost all management tasks of the cluster.
- Query the status of services, applications, or machines
- Create projects, service testing, document management, etc.
- View real-time cluster traffic, locate abnormal issues, etc.
- Issue traffic control rules such as traffic distribution and parameter routing
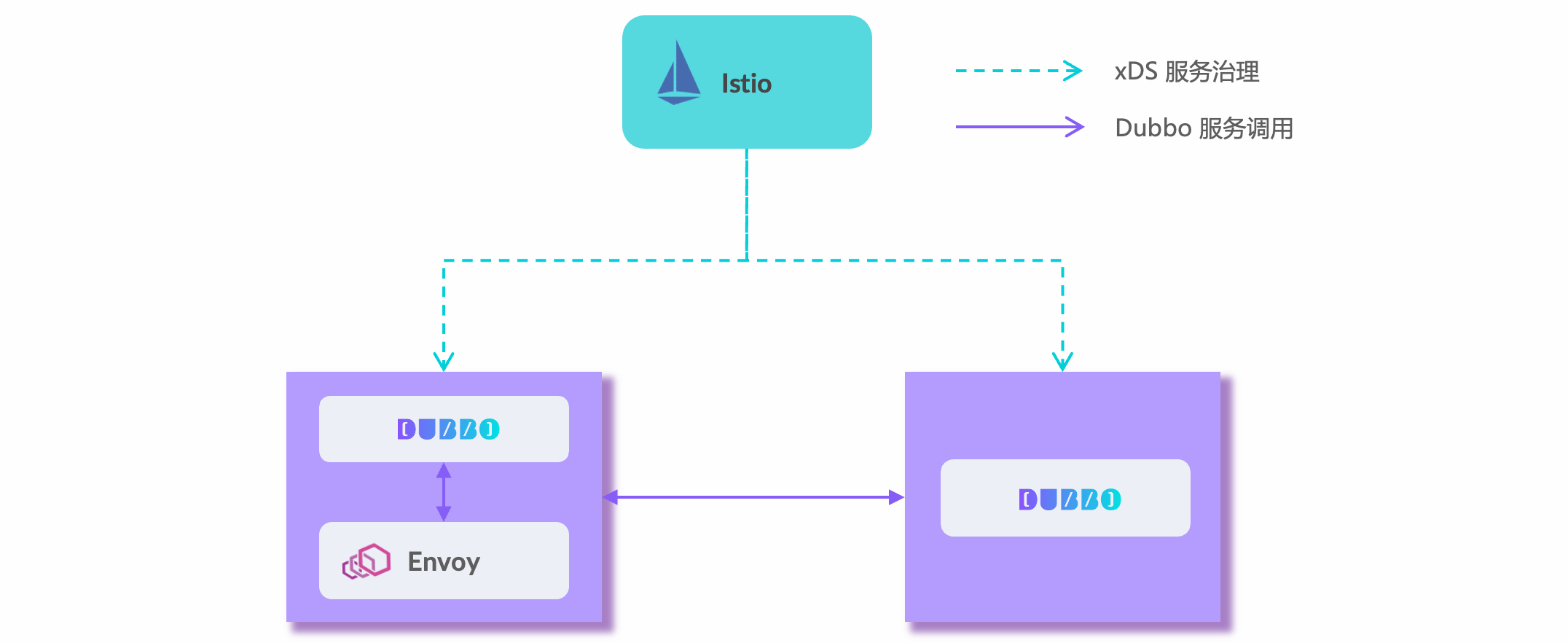
Service Mesh
Integrate Dubbo into service mesh governance systems like Istio.