Attention: The feature described in this doc is still under development or is in a very early stage, please keep updated!
Adaptive Load Balancing and Flow Control
Overview
The flexible services discussed in this article mainly refer to the functions of load balancing on the consumer side and traffic limiting on the provider side. In previous versions of Dubbo,
- The load balancing focused more on fairness, meaning the consumer chooses equally from the provider, which didn’t perform ideally in some cases.
- The traffic limiting only provided static schemes, requiring users to set a static maximum concurrency value on the provider, which was not easy for users to determine.
We made improvements to address these issues.
Load Balancing
Usage Introduction
In the original Dubbo versions, there were five loading balancing schemes available: Random, ShortestResponse, RoundRobin, LeastActive, and ConsistentHash. Except for ShortestResponse and LeastActive, the others mainly considered fairness and stability.
For ShortestResponse, its design aims to select the provider with the shortest response time to improve overall system throughput. However, two issues arise:
- In most scenarios, the response times of different providers do not show significant differences, making this algorithm degrade to random selection.
- The response time does not always represent the machine’s throughput capacity. For
LeastActive, it believes traffic should be allocated to machines with fewer active connections, but it similarly fails to reflect the machine’s throughput capacity.
Based on this analysis, we propose two new load balancing algorithms. One is a simple P2C algorithm based on fairness, while the other is an adaptive method that attempts to dynamically assess the throughput capacity of the provider machines and allocate traffic accordingly to improve overall system performance.
Overall Effect
The effectiveness experiments for load balancing were conducted under two different conditions: balanced provider machine configurations and configurations with large discrepancies.
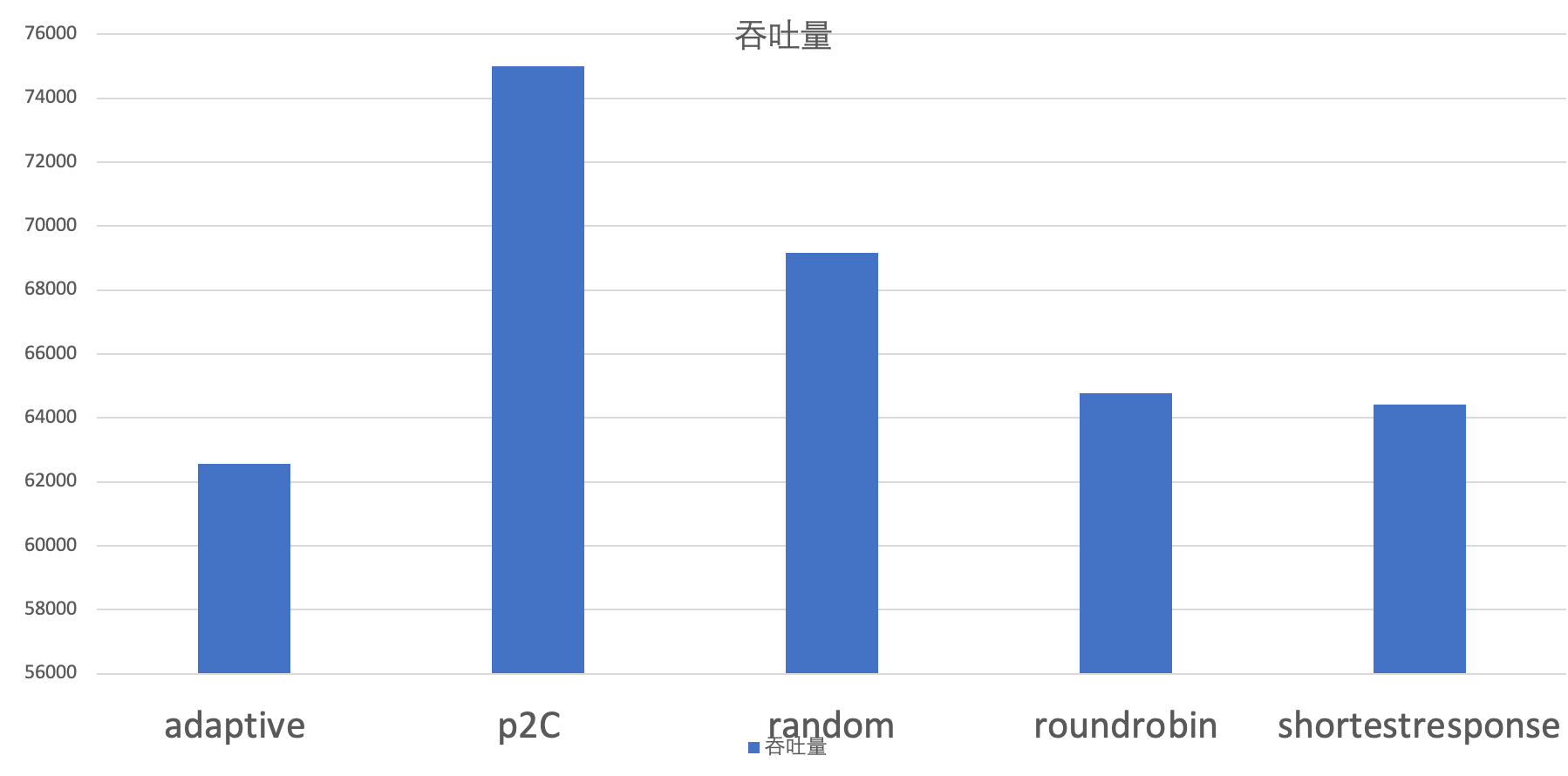
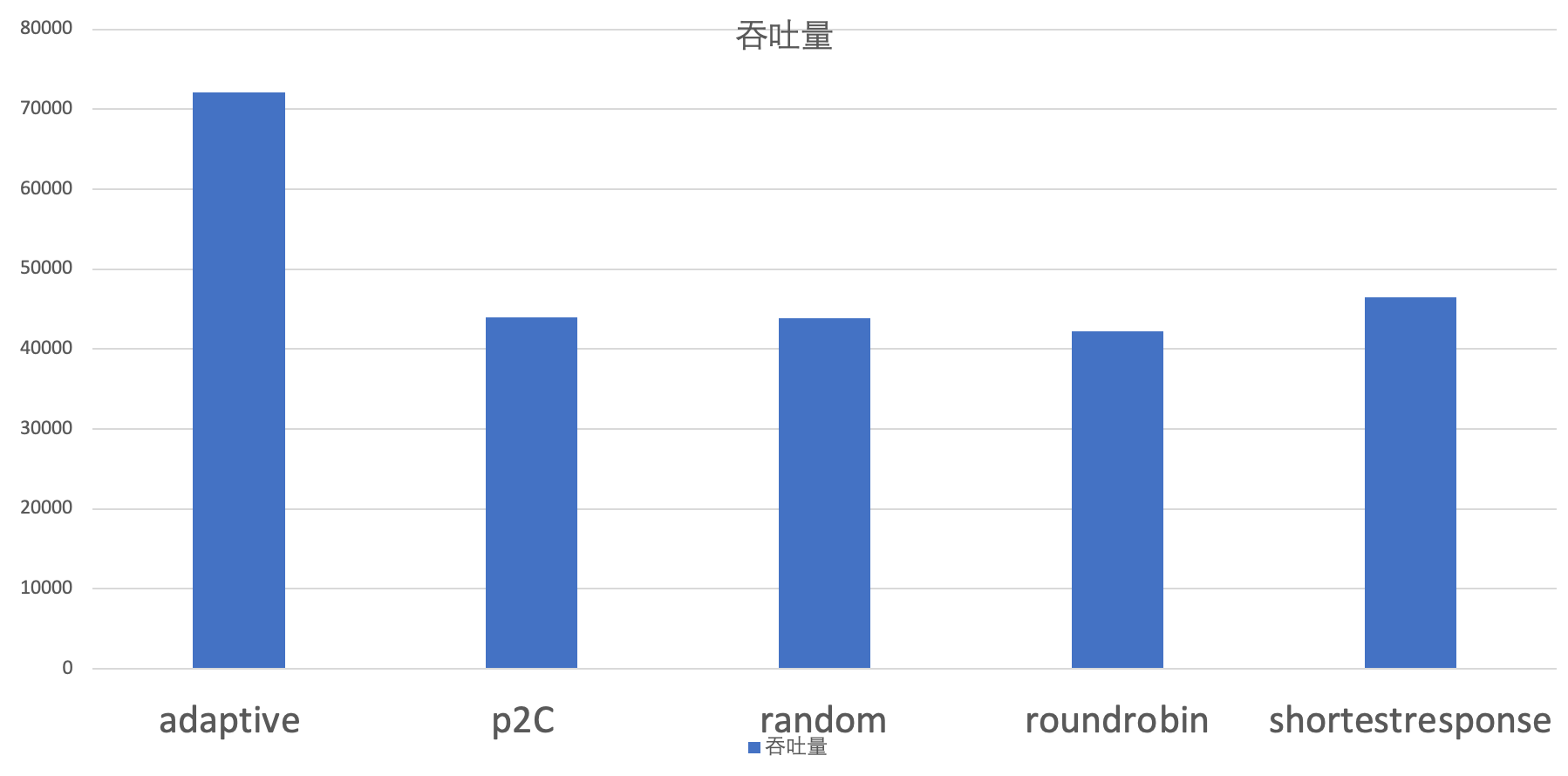
Usage Method
Usage method of Dubbo Java implementation is the same as the original load balancing method. Just set “loadbalance” to “p2c” or “adaptive” on the consumer side.
Code Structure
The algorithm implementation of load balancing only needs to inherit from the LoadBalance interface in the existing load balancing framework.
Principle Introduction
P2C Algorithm
The Power of Two Choice algorithm is simple yet classic, mainly as follows:
- For each call, make two random selections from the available provider list, selecting two nodes, providerA and providerB.
- Compare providerA and providerB, choosing the one with the smaller “current active connection count”.
Adaptive Algorithm
Related Metrics
cpuLoad
 . This metric is obtained from the provider machine and passed to the consumer via the invocation’s attachment.
. This metric is obtained from the provider machine and passed to the consumer via the invocation’s attachment.rt rt is the time taken for an RPC call, measured in milliseconds.
timeout timeout is the remaining timeout for this RPC call, measured in milliseconds.
weight weight is the service weight set.
currentProviderTime The time on the provider side when calculating cpuLoad, measured in milliseconds.
currentTime currentTime is the last calculated load time, initialized to currentProviderTime, measured in milliseconds.
multiple

lastLatency


beta Smoothing parameter, defaulting to 0.5.
ewma Smooth value of lastLatency

inflight inflight is the number of requests not yet returned on the consumer side.

load For a candidate backend machine x, if the time since the last call is greater than 2 * timeout, its load value is 0. Otherwise,

Algorithm Implementation
Still based on the P2C algorithm.
- Make two random selections from the candidate list to get providerA and providerB.
- Compare the load values of providerA and providerB, selecting the smaller one.
Adaptive Traffic Limiting
Unlike load balancing running on the consumer side, traffic limiting operates on the provider side. Its purpose is to limit the maximum number of concurrent tasks processed by the provider. The processing capacity of a server machine theoretically has an upper limit, and when a large number of requests occur in a short period, it can lead to undelivered requests and overload the machine. This scenario can lead to two issues:
- Due to backlogged requests, all requests may have to wait a long time to be processed, leading to service paralysis.
- Prolonged server overload poses a risk of downtime.
Therefore, when overload risks are present, it is better to reject some requests. In previous versions of Dubbo, traffic limiting was achieved by setting a static maximum concurrency value on the provider side. However, in scenarios with many services, complex topology, and dynamically changing processing capabilities, calculating a static value is difficult.
Based on these reasons, we require an adaptive algorithm that can dynamically adjust the maximum concurrency value of server machines to process as many received requests as possible while ensuring the machine does not overload. Therefore, we implemented two adaptive traffic limiting algorithms in the Dubbo framework: HeuristicSmoothingFlowControl based on heuristic smoothing and AutoConcurrencyLimier based on a window.
Usage Introduction
Overall Effect
The effectiveness experiments for adaptive traffic limiting were conducted under conditions of large provider machine configurations, and to highlight the effects, we increased the complexity of individual requests, set the timeout as large as possible, and enabled the retry functionality on the consumer side.
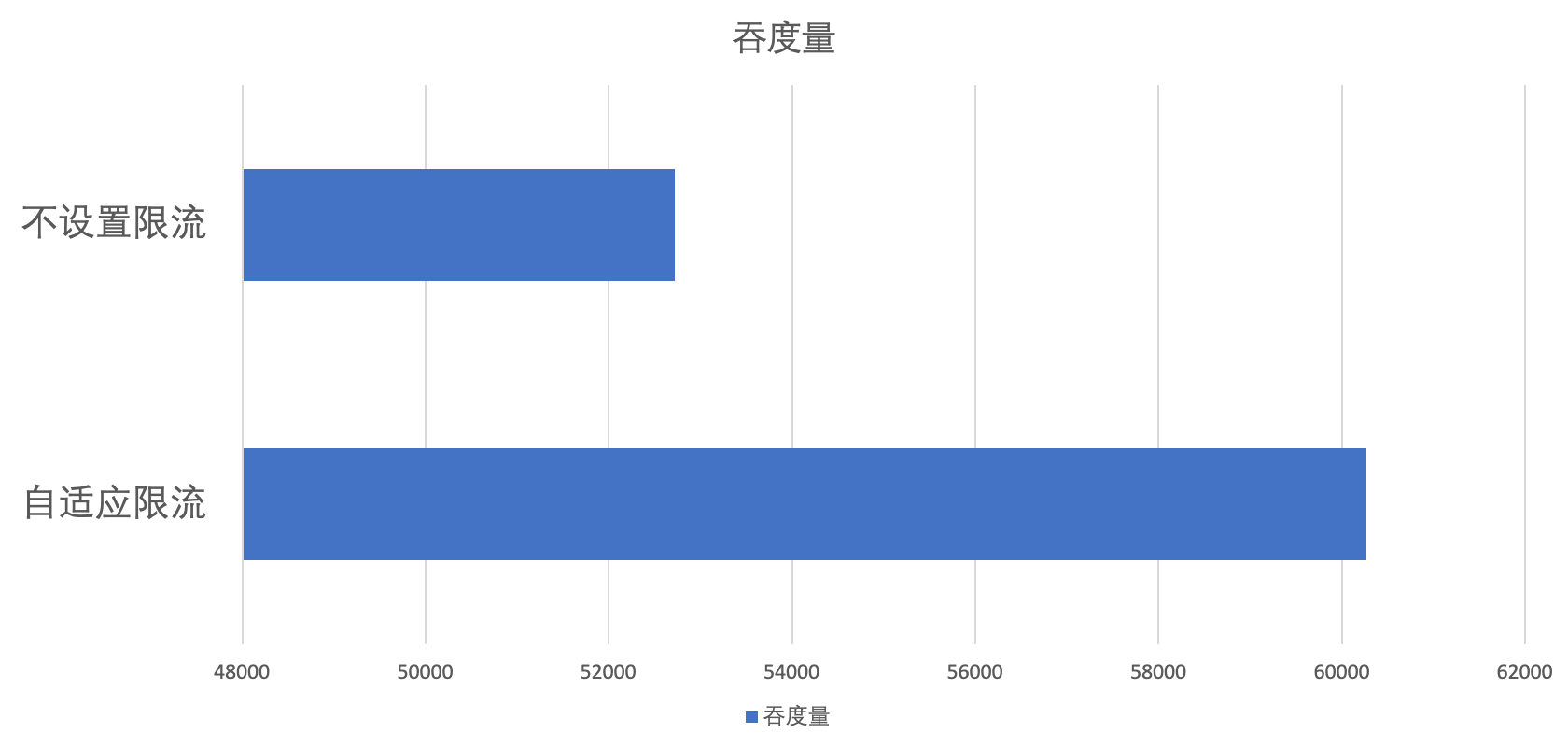
Usage Method
To ensure the presence of multiple nodes on the server side and the enabling of retry strategies on the consumer side, the traffic limiting function can perform better.
Method to enable adaptive traffic limiting in Dubbo Java implementation is similar to setting a static maximum concurrency value, simply set “flowcontrol” to “autoConcurrencyLimier” or “heuristicSmoothingFlowControl” on the provider side.
Code Structure
- FlowControlFilter: the filter on the provider side responsible for implementing traffic control based on the results of the limiting algorithm.
- FlowControl: the interface for limiting algorithms implemented based on Dubbo’s SPI. Specific implementation algorithms for traffic limiting need to inherit from this interface and be usable via Dubbo’s SPI.
- CpuUsage: periodically retrieves relevant CPU metrics.
- HardwareMetricsCollector: methods for obtaining hardware-related metrics.
- ServerMetricsCollector: methods for obtaining metrics required for traffic limiting based on sliding windows. For example, QPS, etc.
- AutoConcurrencyLimier: specific implementation algorithm for adaptive traffic limiting.
- HeuristicSmoothingFlowControl: specific implementation method for adaptive traffic limiting.
Principle Introduction
HeuristicSmoothingFlowControl
Related Metrics
alpha alpha is the acceptable delay increase, defaulting to 0.3.
minLatency The minimum latency value in a time window.
noLoadLatency noLoadLatency is the delay without any queue time. This is an inherent property of server machines but is not constant. In the HeuristicSmoothingFlowControl algorithm, we determine the current noLoadLatency based on the CPU usage. When CPU usage is low, we consider minLatency as noLoadLatency. When CPU usage is moderate, we use a smooth update of noLoadLatency’s value with minLatency. When CPU usage is high, noLoadLatency’s value remains unchanged.
maxQPS The maximum QPS within a time window.
avgLatency The average latency over a time window, measured in milliseconds.
maxConcurrency The calculated maximum concurrency value for the current service provider.

Algorithm Implementation
When the server receives a request, it first checks whether the CPU usage exceeds 50%. If not, the request is accepted for processing. If it does exceed 50%, the current maxConcurrency value is obtained from the HeuristicSmoothingFlowControl algorithm. If the currently processed request count exceeds maxConcurrency, the request is rejected.
AutoConcurrencyLimier
Related Metrics
MaxExploreRatio Default set to 0.3.
MinExploreRatio Default set to 0.06.
SampleWindowSizeMs The duration of the sampling window, defaulting to 1000 milliseconds.
MinSampleCount The minimum request count for the sampling window, defaulting to 40.
MaxSampleCount The maximum request count for the sampling window, defaulting to 500.
emaFactor Smoothing processing parameter, defaulting to 0.1.
exploreRatio Exploration rate, initially set to MaxExploreRatio. If avgLatency <= noLoadLatency * (1.0 + MinExploreRatio) or qps >= maxQPS * (1.0 + MinExploreRatio), then exploreRatio = min(MaxExploreRatio, exploreRatio + 0.02); Otherwise, exploreRatio = max(MinExploreRatio, exploreRatio - 0.02).
maxQPS The maximum QPS within the window period.

noLoadLatency

halfSampleIntervalMs Half sampling interval, defaulting to 25000 milliseconds.
resetLatencyUs The timestamp for resetting all values next time, including the values within the window and noLoadLatency. Measured in microseconds and initialized to 0.

remeasureStartUs The starting time for resetting the window next time.

startSampleTimeUs The starting time for sampling, measured in microseconds.
sampleCount The number of requests within the current sampling window.
totalSampleUs The sum of latencies for all requests within the sampling window, measured in microseconds.
totalReqCount The total number of requests within the sampling window, differing from sampleCount.
samplingTimeUs The timestamp of the current request’s sampling, measured in microseconds.
latency The latency of the current request.
qps The QPS value within this time window.

avgLatency The average latency within the window.

maxConcurrency The maximum concurrency value calculated in the previous window for the current period.
nextMaxConcurrency The next maximum concurrency value calculated for the current window.

Little’s Law
- When the service is in a stable state: concurrency = latency * qps. This is the foundation of the adaptive traffic limiting theory.
- When requests do not overload the machine, latency remains stable, and qps and concurrency are linearly related.
- When an excessive number of requests occur in a short time, leading to service overload, concurrency will increase with latency, while qps will tend to stabilize.
Algorithm Implementation
The algorithm execution process of AutoConcurrencyLimier is similar to HeuristicSmoothingFlowControl. The main difference is:
AutoConcurrencyLimier is window-based. Only when a certain amount of sample data accumulates within the window will the maxConcurrency value be updated using the window data. Additionally, it uses the exploreRatio to explore the remaining capacity.
Moreover, every so often, max_concurrency will be automatically reduced for a period to handle the rise in noLoadLatency, as estimating noLoadLatency requires the service to be in a low-load state, making the reduction of maxConcurrency unavoidable.
Since max_concurrency < concurrency, the service will reject all requests, and the traffic limiting algorithm sets “emptying all the time spent waiting for queued requests” to 2 * latency, ensuring that the majority of samples for minLatency were not waiting in line.