Introduction to Trie Prefix Tree
Introduction
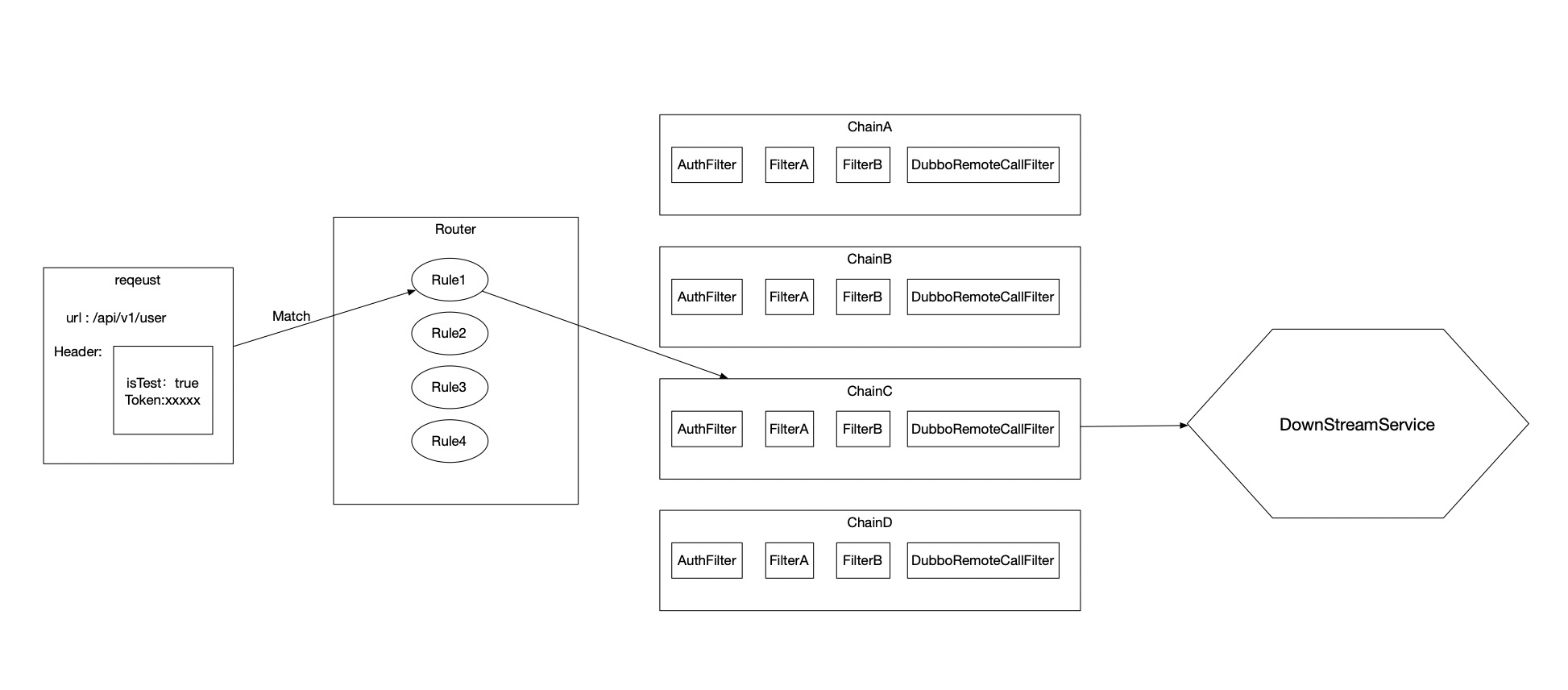
One of the cores of the gateway is the routing logic, which determines how a request needs to be processed and which downstream service it should be forwarded to.
About 80% of routing requirements are URL-based. It is necessary to clearly describe how URLs or sets of URLs with certain characteristics correspond to a series of downstream processing strategies.
For example, URLs starting with ‘/test/’ route to the testing environment cluster, while URLs starting with ‘/release/user/’ route to the production environment’s user services cluster.
Additionally, as the entry point for all requests, every millisecond of delay accumulates across the entire business in a mesh scenario, where delays can further magnify with the depth of the call chain. According to the standard for production environments, response times of <=7 milliseconds set a very demanding performance requirement for rule matching. Performance must not degrade as the number of rules increases.
Usage Introduction
This section describes how Pixiu’s configuration file delineates URL-related routing rules from the user’s perspective. (Next, we will explain how to configure URL routing rules.)
Below is a sample Pixiu API configuration file, which will be parsed to create a corresponding memory model as the initial state for Pixiu’s routing configuration. Subsequently, the memory model obtained by parsing will be modified by the RDS protocol to achieve dynamic routing logic. The content related to the RDS protocol (RDS: the part of the xDS protocol that describes routing rules) will not be detailed here. Let’s focus on the resource section.
The path part under resource represents the URL-related routing description discussed above. This means that URLs that match the path description will be successfully matched.
name: server
description: server sample
resources:
- path: '/api/v1/test-dubbo/user/name/:name'
type: restful
description: user
methods:
- httpVerb: GET
enable: true
timeout: 1000ms
inboundRequest:
requestType: http
uri:
- name: name
required: true
integrationRequest:
requestType: dubbo
mappingParams:
- name: uri.name
mapTo: 0
mapType: "string"
applicationName: "UserProvider"
interface: "com.dubbogo.server.UserService"
method: "GetUserByName"
group: "test"
version: 1.0.0
clusterName: "test_dubbo"
Matched requests will be converted into the Dubbo protocol and forwarded to the test_dubbo cluster to call the GetUserByName service under com.dubbogo.server.UserService.
Let’s further focus on the following scope:
path: '/api/v1/test-dubbo/user/name/:name'
To describe a URL or a group of URLs clearly, the routing engine needs to have the following capabilities:
- URLs can include variables; ‘/api/v1/test-dubbo/user/name/:name’ indicates that the value of the sixth segment separated by “/” is used as the value of the variable name, which is passed to the downstream filter for usage.
- Wildcards are required.
- represents a wildcard for any single character at one level; a path description like ‘/api/*/test-dubbo/user/name/:name’ indicates that the specific version is not essential, and any URL that matches, regardless of the version, will be processed and forwarded using the same logic.
- ** represents wildcards for multiple levels; it can only exist at the end of the URL to avoid ambiguity. A path like ‘/api/v1/**’ indicates that all V1 version URLs will adopt the same logic.
To use Pixiu correctly, you may need to understand the following content.
Priority
This is not a novel concept; it is a priority logic commonly possessed by frameworks like Spring in Java:
- Wildcard priorities are lower than specific ones. The priority of ‘/api/v1/**’ is lower than that of ‘/api/v1/test-dubbo/user/name/:name’. If two resources adopt the aforementioned path configurations, which resource should take effect upon receiving a request for ‘/api/v1/test-dubbo/user/name/yqxu’ ? According to the principle that wildcards are lower than specifics, the rule ‘/api/v1/test-dubbo/user/name/:name’ will take effect.
- Deeper levels have higher priorities. The comparison between ‘/api/v1/’ and ‘/api/v1/test-dubbo/’; if both descriptions are satisfied, ‘/api/v1/test-dubbo/**’ will take effect due to its deeper level.
- Wildcard ‘/*’ has a higher priority than ‘/**’.
- Variables are equivalent to wildcards.
Conflict Handling
The priority rule is just one way to resolve conflicts. When multiple URL descriptions match simultaneously, the one with the higher priority will take effect. However, the priority strategy cannot cover all cases.
If two resource paths are configured to be exactly the same but forwarded to different downstream services, a conflict will occur. Pixiu’s strategy for handling conflicts is to fail fast; if conflicting rules are found during the initialization phase of Pixiu, the startup will fail, allowing developers to detect and address the issue early.
Principle Introduction
Upon selecting the technology and determining the use of Pixiu to handle unforeseen situations and potential bugs, developers need to have a deeper understanding of the routing principles of Pixiu.
Next, we will detail the relevant principles and implementations of the routing engine for those interested.
Those who read this part are likely to subconsciously think of the structure of a trie. Utilizing a trie structure can achieve performance optimization in matching irrespective of the number of existing rules.
A trie that stores strings as nodes can express URLs.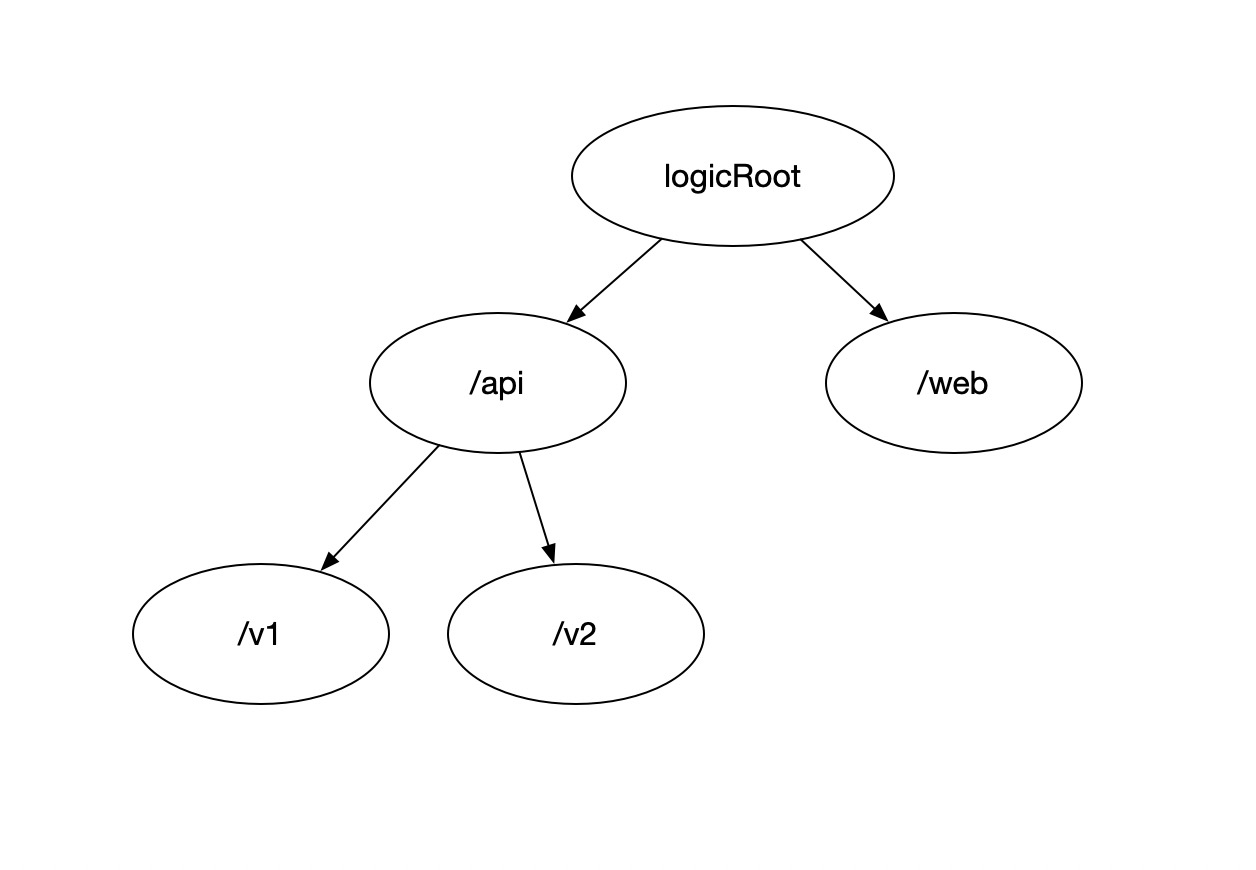
This depiction is equivalent to the URL set ‘/api/v1’, ‘/api/v2’, ‘/web’.
Maintaining a standard trie involves several key operations:
- Trie Node Lookup (find): Starting from the root, traverse the trie; ‘/api/v2’ is called a path that searches for the specified path in the current level. If it exists, continue matching the remaining path in the subtree. For ‘/api/v2’, the search begins at the logic root for ‘/api’, continuing under ‘/api’ for the remainder ‘/v2’.
- Adding to Trie Nodes (add): Attempt to find the specified node; if it does not exist, create a new node. Assuming an empty tree state while adding ‘/api/v1’, the logic root will not find ‘/api’, creating it before searching under ‘/api’ for ‘/v1’, which also does not exist, leading to its creation.
- URL Matching in Trie (match): In this simplest version, the matching logic is identical to the specified node lookup logic.
Some simple operations that do not involve recursion or reuse the above logic:
- Modifying a Trie Node (modify): Find the specified node using the find logic and modify the node content through the set method or direct assignment.
- Deleting a Trie Node (delete): Using the modify logic, change isDeleted to true and modify the node content to empty. The node’s memory is not released.
- Rebuilding the Trie (rebuild): Traverse all nodes and add them to a new tree. If isDeleted is true, it is not added to the new tree, creating a copy via the rebuild operation.
As noted, a standard trie structure still has gaps in its capabilities for a general routing engine, lacking generalized representation and variable expression abilities. Let’s look at how to improve this.
Adding subordinate trees that describe generalized logic to form a default component of the subtree.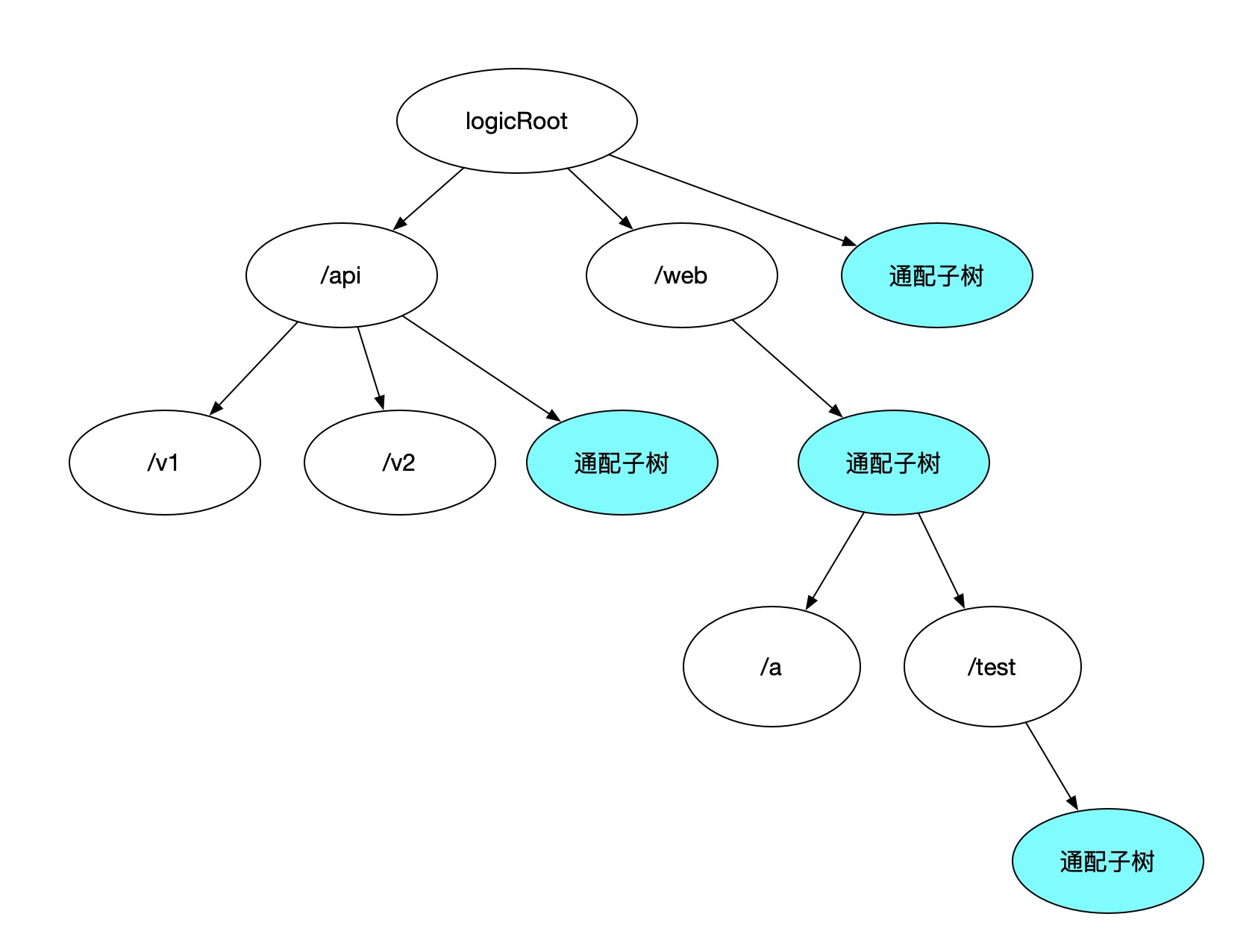
Now our variant trie gains variable expression capability.
How should a URL like ‘/web/:appname/test/*’ be represented in the diagram?
Correct, it should be this path.
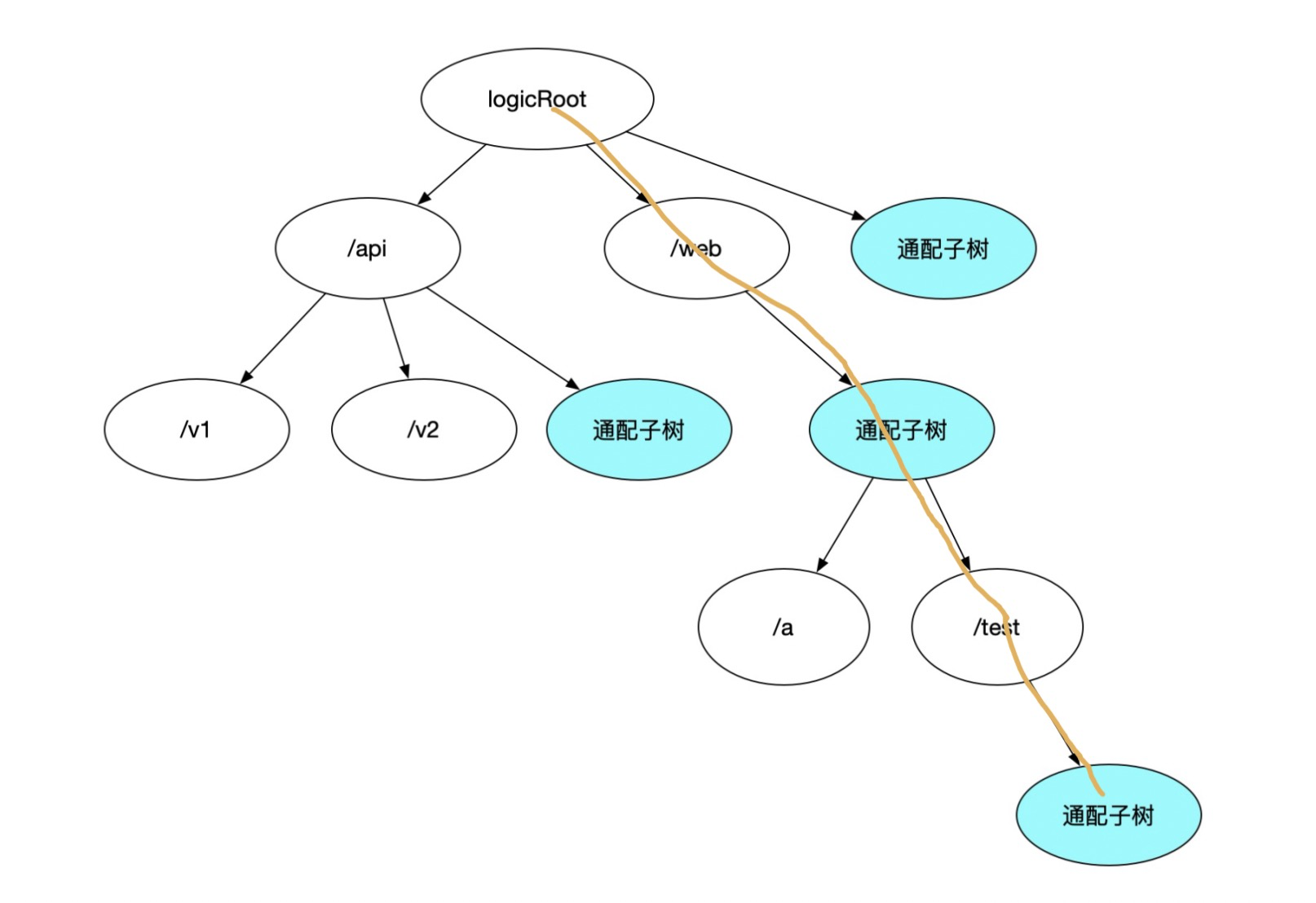
Continuing to analyze whether any key operations in the trie need changes:
- Lookup for a Specific Trie Node:
- If the previous version logic is not modified before processing the ‘/’ node, there should not be any issues: Starting from the root, traverse the trie; ‘/api/v2/’ serves as the path. It finds the specified path in the current level. If it exists, continue matching in the subtree. For example, ‘/api/v2’ first finds ‘/api’ and continues searching for ‘/v2’ in its subtree.
- In this version, handling of the ‘/’ node is added: After ‘/v2’ is ‘/’, which corresponds to a single-level wildcard node. Continue to recursively check whether the wildcard node is empty beneath ‘/v2’. If path is ‘/api/v2/*/test2’, continue the recursive process in the generalized subtree.
- Adding a Trie Node:
- Before adding a ‘/’ node, the previous logic is adequate: attempt to locate the specified node; if it does not exist, create a new node. Given an empty tree state while adding ‘/api/v1/’, the logic root will not find ‘/api’, leading to its creation before checking for ‘/v1’, again leading to its creation if it doesn’t exist.
- This version adds special handling for ‘/*’: After creating ‘/v1’, check for the wildcard subtree. If nonexistent, a single-level wildcard subtree representing V1 will be added, continuing the recursion.
- URL Matching in the Trie: In this version, the comparison for fetch logic needs to enhance backtracking.
- When encountering a wildcard node, the logic prior to it remains unchanged: Starting from the root, traverse the trie; ‘/api/v2/*’ is a designated path that searches for the specified path. If it exists, continue matching in the subtree. ‘/api/v2’ will first find ‘/api’ then continue with ‘/v2’ in its subtree.
- There’s a deviation in handling wildcard nodes versus the find logic: If ‘/v2’ hosts no matching nodes in its ordinary subtree, backtrack to the wildcard subtree to check for matches. In this case, as ‘/v2’ leads to no matches, it should be mentioned that the order in backtracking is critical — whether to search the ordinary subtree first before backtracking to the wildcard subtree depends on the priority rules, and it must search the ordinary subtree first.
However, we currently still lack the expressiveness of multi-level wildcards represented by ‘/’. Analyzing requirement conclusions indicates these wildcards should not have subtrees; they are specialized leaf nodes used for special judgments during match logic backtracking. Continuing to introduce some special nodes evolves this into: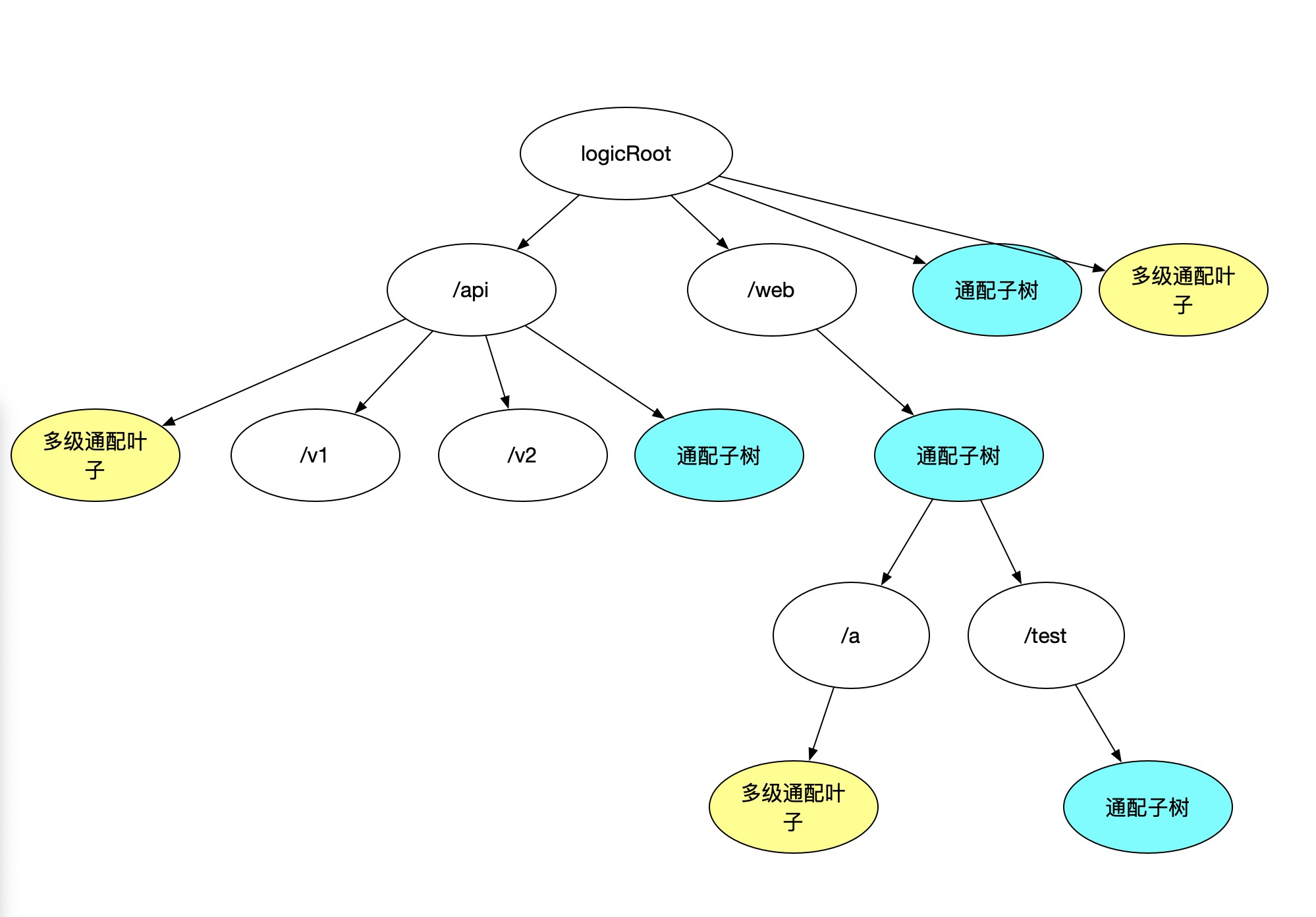
Now, all requirements are sufficed.
Equivalent paths for ‘/api/’: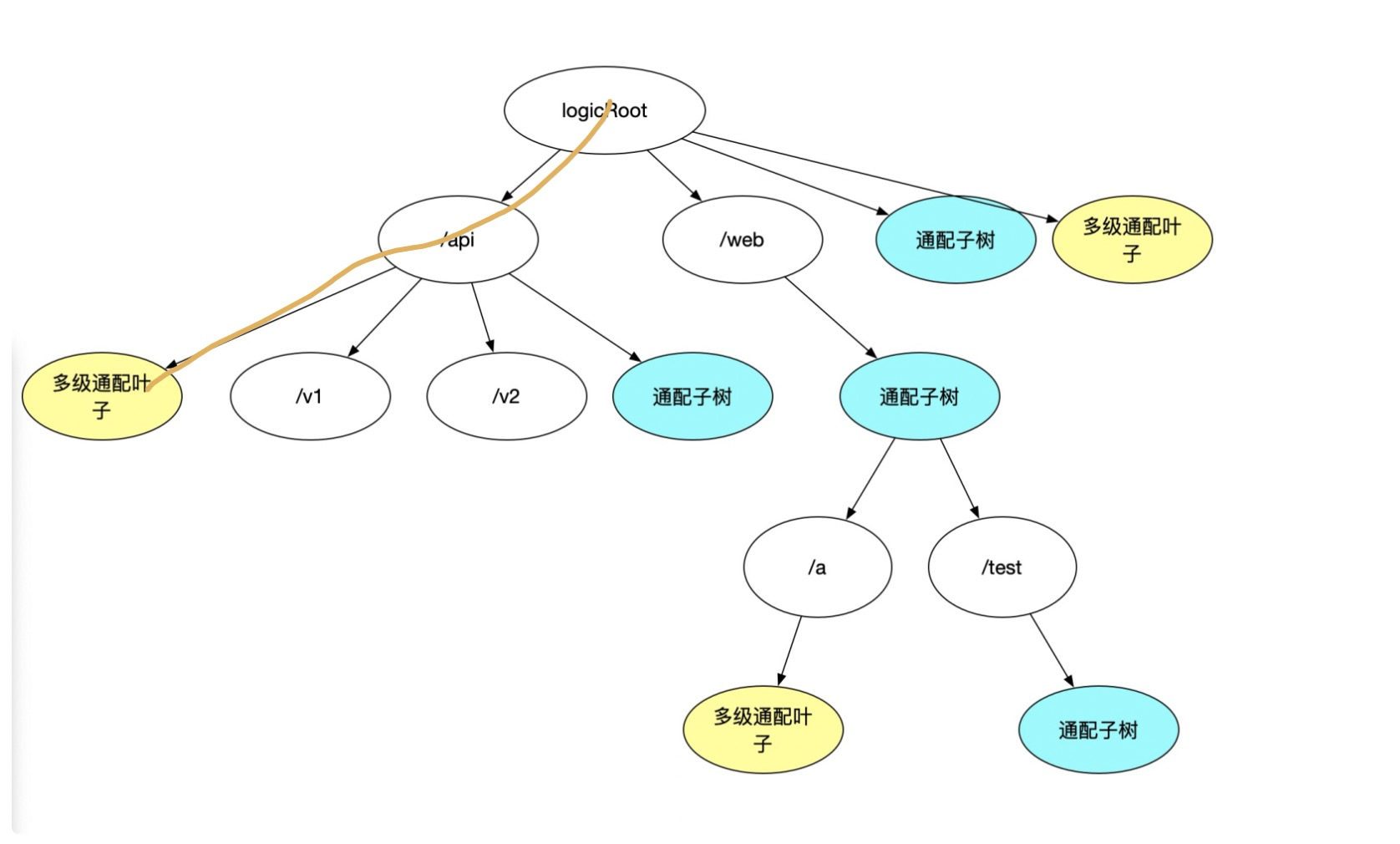
Other logic is largely the same; match logic now has one more level of judgment. If the single-level wildcard subtree still finds no results, check if the multi-level wildcard subtree is empty (one flag would suffice, but a subtree is used here for model uniformity and clarity).
At this point, all capabilities previously discussed can effectively support the relevant operations. Analyzing the complexity, URLs are divided into segments by ‘/’, making matching complexity O(n), where n = number of URL segments. This complex analysis remains indifferent to the quantity of rules stored in the tree. Further analyzing scope of n reveals it is not an unlimited number; some browsers even constrain the URL length to below 2000 characters. Assuming an average segment length of 5, segments would generally be capped at around 400. If n could be considered a constant, the complexity can thus be viewed as O(1).
In brief, explain the difference between find and match, and why both node retrieval methods are necessary. Consider this example: if the tree has already added the path ‘/api/v1/:name/add’, then
find("/api/v1/:name/add") and find("/api/v1/*/add") should yield results during the add process for conflict checking.
Assuming a request comes in with URL ‘/api/v1/:name/add’, match("/api/v1/:name/list") should also yield results, setting the variable name to :name.
If a request with the URL ‘/api/v1/yq/add’ comes in, match("/api/v1/yq/list") should produce results with name being yq, while find("/api/v1/yq/add") will yield no result.
Future Improvements
Currently, a global lock is acquired before reading or writing to the tree. On failure, it will spin until success before proceeding with read or write.
This is done because extensive use of Go’s map structure is present in the code. Concurrent read-write accesses lead to this error: concurrent map read and map write.
The current implementation is as follows: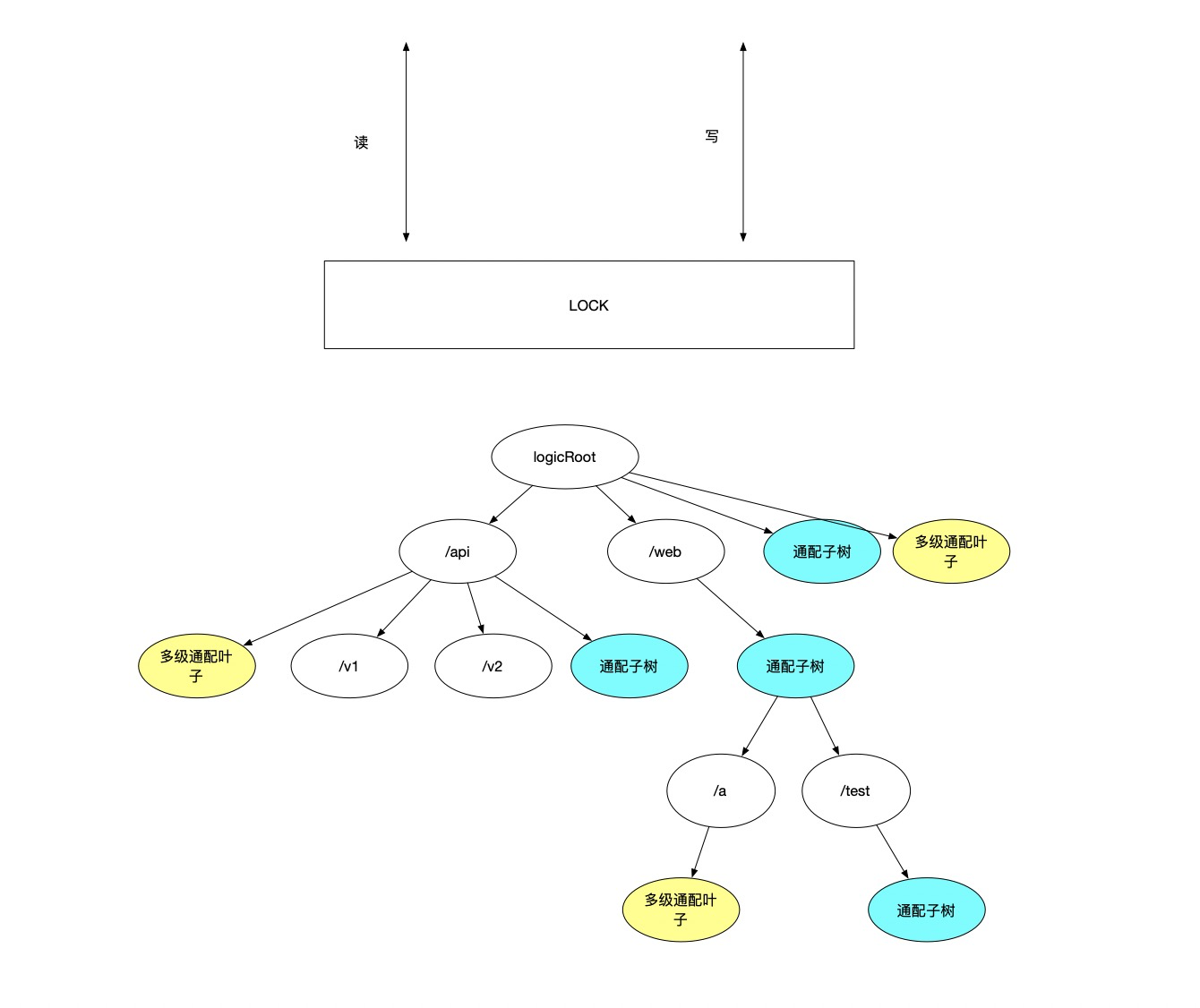
A command queue is introduced, where all user write operations go in first, while separating read and write from each other. One thread is maintained to capture logs and write to the write tree. The read tree, which is purely read, does not require a write thread; hence, no locks are necessary. The write tree, written by only one thread, incurs no competition issues and, therefore, can also operate without locks (write operations are not frequent and are manageable via a single thread).
A configuration defining an effective delay time, say 3s, is set.
Every 3 seconds, the roles of the read and write trees switch. Each trie maintains a cursor for its command queue, indicating which record has been traced in the log where this trie is at, while the writing thread switches references of the writing cursor every 3 seconds.
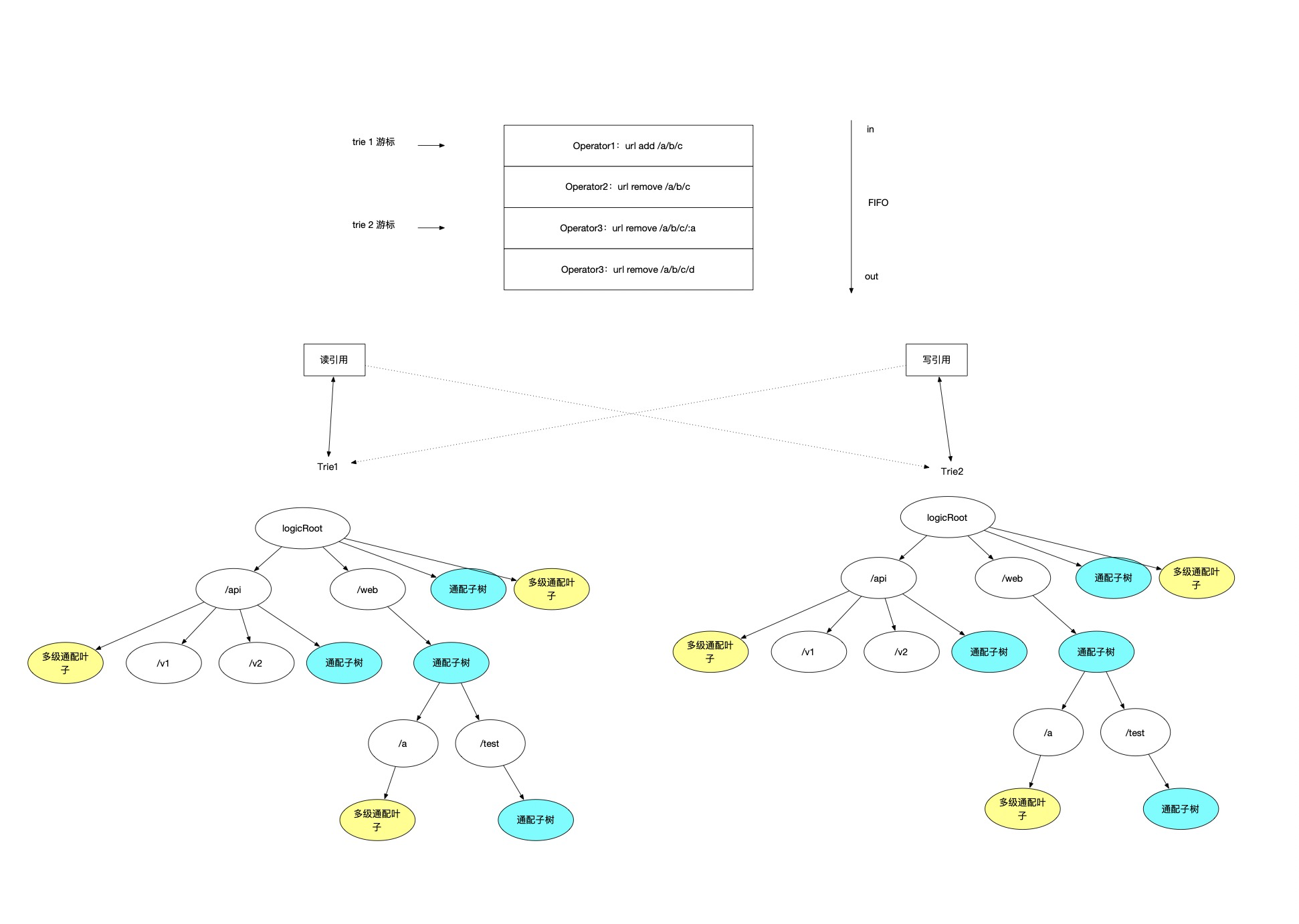
In the above image, the top part represents a first-in-first-out command queue; the logging thread reads from this queue for user write operations. It maintains two cursor indices, index1 and index2; index1 indicates that trie1 has traced its logs to index1 position, while index2 shows trie2 has traced to index2. At any one moment, the logging thread will operate on one reference for write operations, shifting the corresponding index cursor down one space after completing each write. The other trie reference will be used for read operations; all read requests will come from the tree represented by the read reference. Since they are tracing the same log, eventual consistency is guaranteed.
Switching logic:
- First, ensure that the logging thread does empty runs (not suspended, avoiding context switching as it will resume shortly).
- Ensure both trees are not undergoing write operations.
- Switch the read reference to another tree.
- Switch the write reference to another tree.
- Resume the logging thread.
pr:
https://github.com/apache/dubbo-go-pixiu/pull/262
pkg/common/router/trie/trie.go:26