Cluster Fault Tolerance
Background
When cluster calls fail, Dubbo provides various fault tolerance solutions, with failover retry as the default.
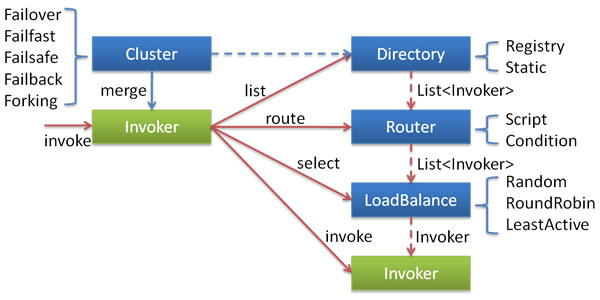
Node relationships:
- Here,
Invokeris an abstraction of a callableServiceofProvider, encapsulating theProvideraddress andServiceinterface information. Directoryrepresents multipleInvokers, which can be viewed asList<Invoker>, but unlikeList, its values may change dynamically, such as changes pushed by the registry.Clusterdisguises multipleInvokersinDirectoryas a singleInvoker, transparent to the upper layer, involving fault tolerance logic; if a call fails, it retries another.Routerselects a subset from multipleInvokersbased on routing rules, such as read-write separation and application isolation.LoadBalanceselects a specificInvokerfor the current call from multipleInvokers, involving load balancing algorithms; if a call fails, it needs to reselect.
Cluster Fault Tolerance Modes
You can extend the cluster fault tolerance strategy. See: Cluster Extension
Failover Cluster
Automatically switches on failure, retrying other servers. Typically used for read operations, but retries introduce longer delays. The retry count can be set with retries="2" (excluding the first attempt).
Retry count configuration:
<dubbo:service retries="2" />
or
<dubbo:reference retries="2" />
or
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
Tip
This configuration is the default configuration.Failfast Cluster
Fast failure, initiating only one call, error on failure immediately. Typically used for non-idempotent write operations, such as adding records.
Failsafe Cluster
Safe failure, directly ignoring exceptions. Typically used for writing audit logs and similar tasks.
Failback Cluster
Automatic recovery from failure, recording failed requests and resending them at intervals. Typically used for message notification operations.
Forking Cluster
Parallel calls to multiple servers, returning as soon as one succeeds. Typically used for read operations with high real-time requirements but requires more service resources. The maximum parallel number can be set with forks="2".
Broadcast Cluster
Broadcast calls to all providers, calling them one by one; if any one fails, it reports an error. Typically used to notify all providers to update local resources like caches or logs.
In a broadcast call, you can configure the proportion of node call failures with broadcast.fail.percent. When this proportion is reached, the BroadcastClusterInvoker will stop calling other nodes and throw an exception directly. The value of broadcast.fail.percent ranges from 0 to 100. By default, an exception is only thrown when all calls fail. The broadcast.fail.percent parameter takes effect in versions 2.7.10 and above.
Broadcast Cluster configuration for broadcast.fail.percent.
broadcast.fail.percent=20 means that an exception will be thrown when 20% of the nodes fail, with no further calls to other nodes.
@reference(cluster = "broadcast", parameters = {"broadcast.fail.percent", "20"})
Tip
Supported since2.1.0Cluster Mode Configuration
Configure the cluster mode as follows on both the service provider and consumer sides.
<dubbo:service cluster="failsafe" />
or
<dubbo:reference cluster="failsafe" />