Service Discovery
Service discovery, that is, the ability of the consumer to automatically discover the list of service addresses, is a key capability that the microservice framework needs to have. With the help of automated service discovery, microservices can be implemented without knowing the deployment location and IP address of the peer. communication.
Method to realize
There are many ways to realize service discovery. Dubbo provides a Client-Based service discovery mechanism. Usually, additional third-party registry components need to be deployed to coordinate the service discovery process, such as commonly used Nacos, Consul, Zookeeper, etc. Dubbo itself also provides the connection to various registry components, and users can choose flexibly.
working principle
Dubbo is based on the automatic service discovery capability of the consumer, and its basic working principle is as follows:
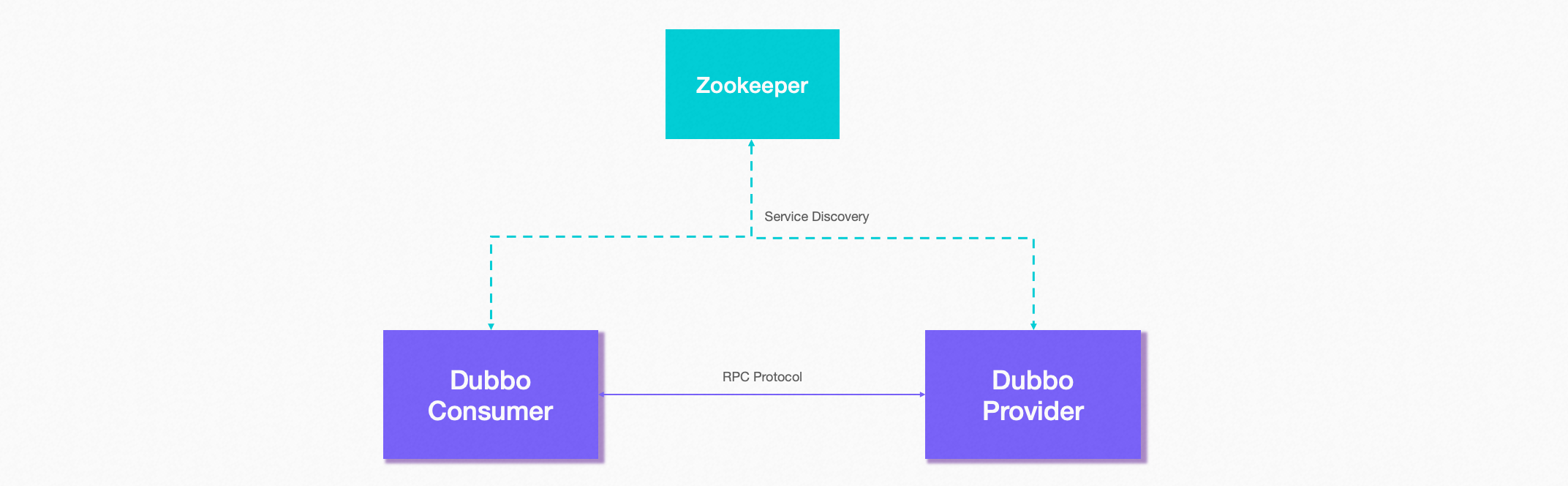
A core component of service discovery is the registry, Provider registers addresses to the registry, and Consumer reads and subscribes to the Provider address list from the registry. Therefore, to enable service discovery, you need to add registry configuration to Dubbo:
Take dubbo-spring-boot-starter as an example, add registry configuration
# application.properties
dubbo
registry
address: zookeeper://127.0.0.1:2181
Introduction to application-level service discovery
In summary, the application-level service discovery introduced by Dubbo3 mainly has the following advantages
- Adapt to cloud-native microservice changes. The infrastructure capabilities in the cloud-native era are continuously released upwards. Platforms such as Kubernetes integrate the conceptual abstraction of microservices. Dubbo3’s application-level service discovery is a general model for adapting various microservice systems.
- Improved performance and scalability. The service governance that supports ultra-large-scale clusters has always been Dubbo’s advantage. By introducing an application-level service discovery model, it essentially solves the storage and push pressure of the registry address data, and the corresponding address calculation pressure on the consumer side also drops by an order of magnitude. ; The cluster size has also become predictable and assessable (it has nothing to do with the number of RPC interfaces, but only with the instance deployment scale).
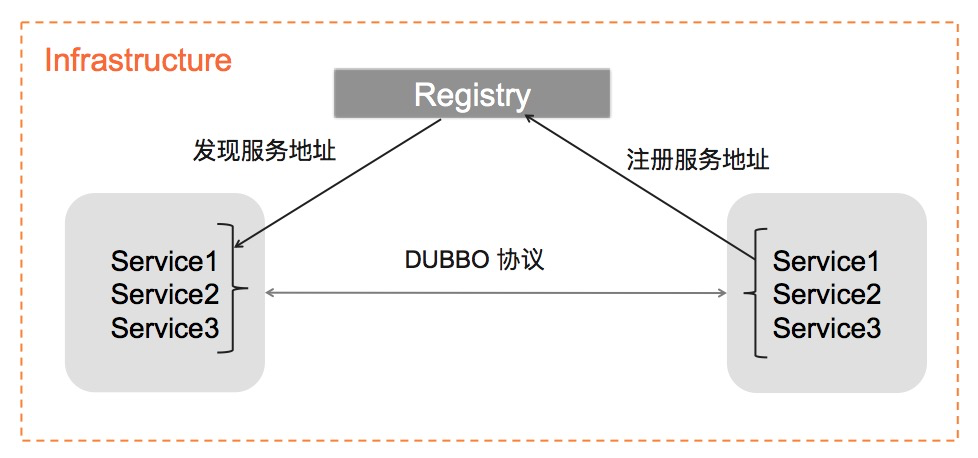
The following figure shows the service discovery model of Dubbo2: Provider registers the service address, Consumer coordinates with the registration center and discovers the service address, and then initiates communication with the address. This is the classic service discovery process used by most microservice frameworks. The special feature of Dubbo2 is that it also integrates the information of “RPC interface” into the address discovery process, and this part of information is often closely related to specific business definitions.
After accessing the cloud-native infrastructure, the infrastructure incorporates the abstraction of the concept of microservices, and the process of orchestrating and scheduling containerized microservices completes the registration at the infrastructure level. As shown in the figure below, the infrastructure not only assumes the responsibility of the registration center, but also completes the service registration action, and the information of the “RPC interface”, because it is related to specific businesses, is impossible and unsuitable to be hosted by the infrastructure.
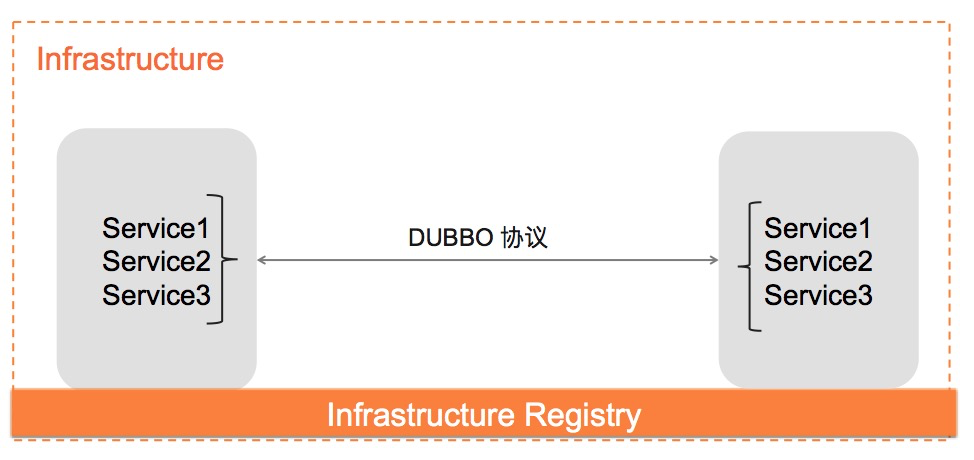
In such a scenario, there are two requirements for Dubbo3’s service registration discovery mechanism: Dubbo3 needs to abstract a common address mapping model that has nothing to do with business logic in the original service discovery process, and ensure that this part of the model is reasonable enough to support entrusting the registration behavior and storage of addresses to the underlying infrastructure Dubbo3’s unique business interface synchronization mechanism is an advantage that Dubbo3 needs to retain. It needs to be resolved through its own mechanism within the framework on top of the new address model defined in Dubbo3.
The new service discovery model designed in this way brings greater advantages to Dubbo3 in terms of architecture compatibility and scalability.
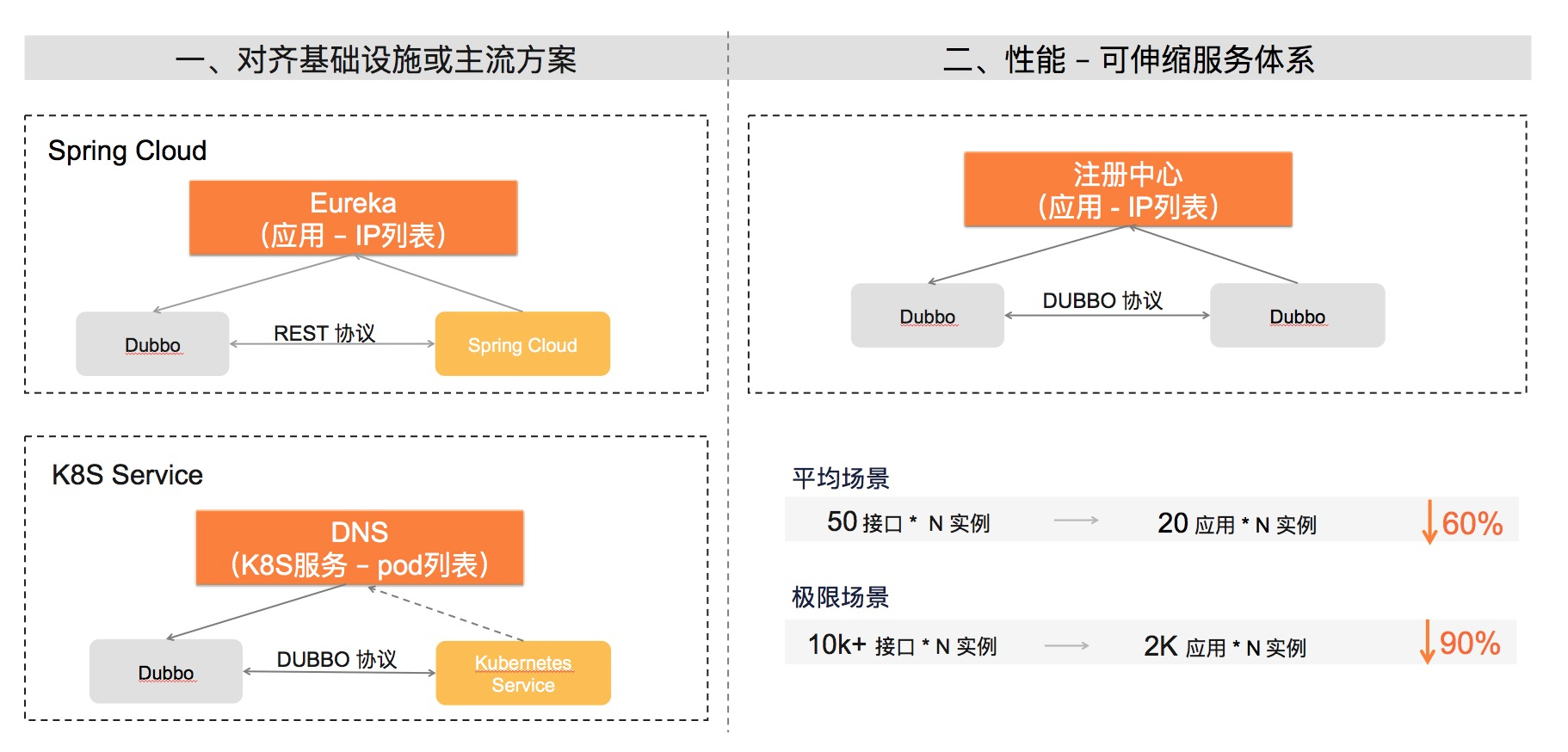
In terms of architectural compatibility, as mentioned above, it is possible for Dubbo3 to reuse the service abstraction capabilities of the underlying infrastructure; on the other hand, other microservice solutions in the industry such as Spring Cloud also follow this model. After opening the address discovery, it becomes possible for users to explore using Dubbo to connect heterogeneous microservice systems.
The Dubbo3 service discovery model is more suitable for building a scalable service system. How to understand this? Here is a simple example to intuitively compare the data flow changes in the address discovery process between Dubbo2 and Dubbo3: Suppose a microservice application defines 100 interfaces (services in Dubbo), You need to register 100 services in the registry. If this application is deployed on 100 machines, then these 100 services will generate a total of 100 * 100 = 10000 virtual nodes; and the same application, For Dubbo3, the new registration discovery model only needs 1 service (only related to the application and has nothing to do with the interface), and only registers 1 * 100 = 100 virtual nodes equal to the number of machine instances to the registration center. In this simple example, the number of addresses registered by Dubbo has dropped to 1/100 of the original, which greatly relieves the storage pressure on the registration center and subscribers. more importantly, The address discovery capacity is completely decoupled from the business RPC definition, and the capacity evaluation of the entire cluster will become more transparent for operation and maintenance: as many machines are deployed as there are loads, it will not be like Dubbo2. Because business RPC reconstruction will affect the stability of the entire cluster service discovery.