Cluster Fault Tolerance
When the cluster call fails, Dubbo provides a variety of fault tolerance schemes, and the default is failover retry.
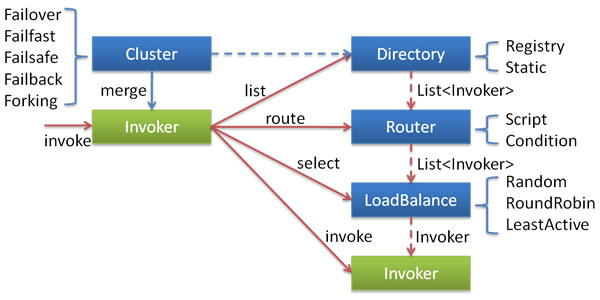
Each node relationship:
- Here
Invokeris an abstraction ofProviderthat can callService,InvokerencapsulatesProvideraddress andServiceinterface information Directoryrepresents multipleInvoker, which can be regarded asList<Invoker>, but different fromList, its value may change dynamically, such as the registration center pushing changesClusterdisguises multipleInvokerinDirectoryas anInvoker, which is transparent to the upper layer. The masquerading process includes fault-tolerant logic. After the call fails, try another oneRouteris responsible for selecting subsets from multipleInvokeraccording to routing rules, such as read-write separation, application isolation, etc.LoadBalanceis responsible for selecting a specific one from multipleInvokers for this call. The selection process includes a load balancing algorithm. After the call fails, it needs to be re-selected
Cluster fault tolerance mode
You can expand the cluster fault-tolerant strategy by yourself, see: Cluster Expansion
Failover Cluster
Automatic switching on failure, when a failure occurs, retry other servers. Usually used for read operations, but retries can introduce longer delays. The number of retries can be set by retries="2" (excluding the first time).
The number of retries is configured as follows:
<dubbo:service retries="2" />
or
<dubbo:reference retries="2" />
or
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
Prompt
This configuration is the default configurationFailfast Cluster
Fail fast, only one call is made, and an error will be reported immediately if it fails. Usually used for non-idempotent write operations, such as adding new records.
Failsafe Cluster
Fail safe, when an exception occurs, just ignore it. Typically used for operations such as writing to audit logs.
Failback Cluster
The failure is automatically recovered, and the failed request is recorded in the background and resent at regular intervals. Typically used for message notification operations.
Forking Cluster
Call multiple servers in parallel, and return as long as one succeeds. It is usually used for read operations with high real-time requirements, but more service resources need to be wasted. The maximum parallelism can be set by forks="2".
Broadcast Cluster
Broadcast calls all providers one by one, and if any one reports an error, it will report an error. Usually used to notify all providers to update local resource information such as cache or logs.
Now in the broadcast call, you can configure the failure ratio of the node call through broadcast.fail.percent. When this ratio is reached, the BroadcastClusterInvoker No other nodes will be called, and an exception will be thrown directly. broadcast.fail.percent ranges from 0 to 100. By default, an exception is thrown when all calls fail. broadcast.fail.percent only controls whether to continue to call other nodes after failure, and does not change the result (if any node reports an error, it will report an error). broadcast.fail.percent parameter Effective in dubbo2.7.10 and above.
Broadcast Cluster configuration broadcast.fail.percent.
broadcast.fail.percent=20 means that when 20% of the nodes fail to call, an exception will be thrown, and no other nodes will be called.
@reference(cluster = "broadcast", parameters = {"broadcast. fail. percent", "20"})
Prompt
2.1.0 started to supportAvailable Cluster
Calls the currently available instance (only one is called), or throws an exception if no instance is currently available. Usually used in scenarios that do not require load balancing.
Mergeable Cluster
Aggregate the call results in the cluster and return the result, usually used together with group. Aggregate the results by grouping and return the aggregated results, such as menu services, use group to distinguish multiple implementations of the same interface, now the consumer needs to call once from each group and return the results, and return the results after merging, so that You can implement aggregated menu items.
ZoneAware Cluster
In the scenario of multi-registry subscription, load balancing between registry clusters. There are four strategies for address selection between multiple registries:
- Specify the priority:
preferred="true"The address of the registration center will be selected first
<dubbo:registry address="zookeeper://127.0.0.1:2181" preferred="true" />
- Same center priority: check the area to which the current request belongs, and give priority to registration centers with the same area
<dubbo:registry address="zookeeper://127.0.0.1:2181" zone="beijing" />
- Weight polling: distribute traffic according to the weight of each registry
<dubbo:registry id="beijing" address="zookeeper://127.0.0.1:2181" weight="100" />
<dubbo:registry id="shanghai" address="zookeeper://127.0.0.1:2182" weight="10" />
- Default: Select an available registry
Cluster mode configuration
Follow the example below to configure cluster mode on the service provider and consumer
<dubbo:service cluster="failsafe" />
or
<dubbo:reference cluster="failsafe" />